
Ამ ბლოგში თქვენ გაეცნობით რეგულრული გამოხატულებების ბირთვს, სინტაქს, მეტა-სიმბოლოებს, კლასებს, მეტა-თანმიმდევრობებს და ა.შ ეს ბლოგი როგორც ყველა დანარჩენი ჩემი ბლოგებისა არ ემსახურება იმას რომ გასწავლოთ როგორ უნდა დაიწეროს კომპლექსური გამოხატულება, მიზანია რომ მიიღოთ ძირითადი ინფორმაცია რაც საშუალებას მოგცემთ საკუთარი კომპლექსური გამოხატულებები შექმნათ, რეგულარული გამოხატულება არ არის ექსკლუზიურად ჯავას მიერ შექმნილი, რომელიც მხოლოდ ჯავა პროგრამულ ენასთან მუშაობას, პიქირით, ის მუშაობს თითქმის ყველა არსებულ პროგრამულ ენასთან (სხვა და სხვა პროგრამულ ენებში რეგექსის გამოყენება ხდება უმნიშვნელო სხვაობებით სინტაქსში), ასე რომ თუ მაგალითად c++-ზე წერთ ან ნებისმიერი სხვა პროგრამულ ენაზე, თქვენთვისაც სასარგებბლო იფნორმაციის მატარებელი იქნება ბლოგი, რეგექსის სინტაქსი, რომელსაც ჯავა იყენებს ახლოს დგას Perl პროგრამული ენის რეგექსის სინტაქსთან.
Რეგულარული გამოხატულება არის გამოხატულება, რომლის მეშვეობითაც მუშაობა ხდება ტექსტურ მონაცემებთან მათი ძიების, შეცვლის, ვალიდაციის ან სხვა სახის მანიპულაციების წარმოების მიზნით. ჯავაში მისი გამოყენება შესაძლებელია java.util.regex პაკეტის მეშვეობით, სადაც სამი კლასი გვაქ Pattern, Matcher და PatternSyntaxException, ეს პაკეტი ალბათ ყველა პარატარა პაკეტია ჯავას ბიბლიოთეკაში, კლასების გამოყენება იმდენად ელემენტალურია რო მათზე ბლოგის ბოლოში ვისაუბრებთ.
Საუბარს დავიწყებთ სინტაქსით, იმისათვის რომ შექმნათ რეგულარული გამოხატულება უნდა ისწავლოთ სინტაქსი, ზუსტად ისე როგორც ისწავლიდით სინტაქს ნებისმიერი სხვა პროგრამული ენის სწავლისთვის, სინტაქსი შეიცავს მეტა-სიმბოლოებს და ამ მეტა-სიმბოლოების საშუალებით ხდება კლასების, ჯგუფების, თანმიმდევრობების და ოდენობების ფორმირება, ერთი წამით თუ დაფიქრდებით მიხვდებით რო ახალ პროგრამულ ენას სწავლობთ, ამიტომაც რეგექს ხშირად პროგრამულ ენას ეძახიან პროგრამულ ენაში (ან პროფესიას პროფესიაში). Მასში იმ სიმბოლოებს რაც თქვენთვის ნაცნობია და ერთი სახის მნიშვნელობა აქვს, რეგექსში სულ სხვა დატვირთვა და მნიშვნელობა გააჩნია. Მეტა-სიმბოლოები რომლის მეშვეობითაც ხდება რეგექსთან მუშაობა ასე გამოიყურება.
Მათ მნიშვნელობას და გამოყენებას ეტაპობრივად გაეცნობით, პირველი რაზეც მინდა გავამახვილო თქვენი ურადღება არის \ სიმბოლო, მას ჯავაში String კლასიც იყენებს, ამიტომ String-ის და რეგექსის გამოყენების დროს ორივეს გათვალისწინება მოგვიწევს, ამაზე უფრო დეტალურად დაბლა ვისაუბრებთ. Თუ დაფაზე ნაჩვენებ რომელიმე სიმბოლოს, სიმბოლოს სახით გამოყენება გსურთ, შეგიძლიათ String კლასის \ სიმბოლო, რეგექს გამოხატულების \ სიმბოლო გამოიყენოთ და ვირტუალური მანქანა აღიქვამს მას ზუსტად ისე როგორც თქვენ გსურთ. Დაუშვათ თუ ტექსტში გვინდა $ ნიშნის მოძიება

Ხედავთ რომ $-ის ნიშანს ორი \\ სიმბოლო უძღვის წინ, სწორედ ასე ხდება მეტა სიმბოლოზე, რომლის მნიშვნელობაც ჯერ არ იცით, განსაკუთრებული მნიშვნელობის ჩამორთმევა, ან შეგიძლიათ \Q \E წინასწარ დეფინირებულ რეგექს კლასებში მოაქციოთ და მიიღოთ იგივე შედეგი.
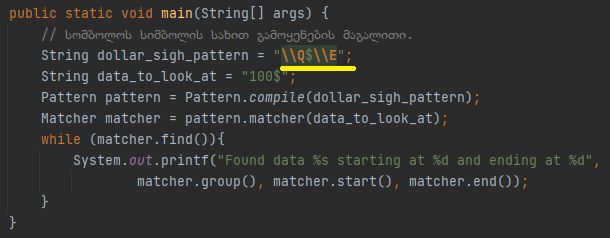
Ხელით რომ არ მოახდინოთ ციტირება (Quoting the symbol) სიმბოლოსი, შეგიძლიათ
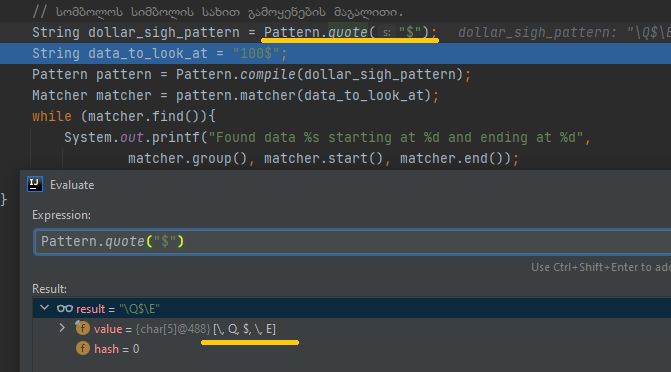
პრედეფინირებული მეთოდი გამოიყენოთ, რომელიც ზუსტად იგივე ოპერაციას ასრულებს რასაც თქვენს მიერ დაწერილი \Q\E ციტირება. Რაც შედეგად გვიბრუნებს

Რეზულტატს, რომელიც გვეუბნება რო მოხდა $-ის ნიშნის მოძიება მე-3 და მ-4 ინდექს შორის. რგორც ხედავთ სიმბოლოს მოძიება მე-3 - მე-4 ინდექსებზე მოხდა, თუ ინდექსირება ისე ხდება როგორც მიჩვეული ვართ, ანუ ათვლა თუ იწყება 0-ან მაშინ მეოთხე ინდექსი ტექსტს არ გააჩნია 100$ ინდექსირების სისტემაში იქნება 0-1-2-3-ზე, მეოთხე საიდან მოვიდა? Რეგექსის კონვენციის მიხედვით ინდექსირება ინკლუზიურად იწყება და ექსკლუზიურად მთავრდება, თუ ვერ მიხვდით ეს რას ნიშნავს, შემდეგი ფოტო ნათელს მოფენს კონვენციას,
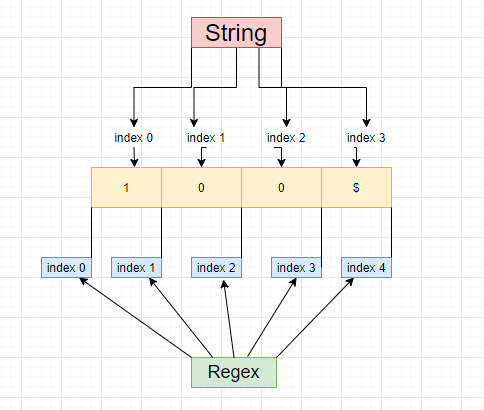
Რომელზეც ნაჩვენებია, String-ის ინდექსირება სადაც ყველა ბგერა საკუთარ ინდექსზეა განთავსებული და რეგექსის ინდექსირება სადაც ერთი ბგერის სასრული ინდექსი, საწყისი ინდექსია შემდეგი ბგერის.
Როგორც მაღლა ვახსენე რეგულარული გამოხატულება არის მძლავრი ხელსაწყო ტექსთან მუშაობისთვის, ხშირად მოხვდებით სიტუაციაში პროგრამირების დროს სადაც იდეალურ გამოსავლად რეგექსის გამოყენებას ხედავთ, დაუშვათ ახდენთ json ფაილის პარსირებას, რომელშიც დეფინირებულია boolean - key, True ღირებულებით, თუ რეგექსში გაატარებთ თქვენ მონაცემებს და მოიძიებთ ყველა boolean ღირებულებას ფაილში (შენიშვნა: რეალურ json ფაილში boolean ღირებულებას ტექსტური (True) წარმომადგენლობით თითქმის არასდროს შეხვდებით და თუ შეხვდებით მაშინ ფაილი სავარაუდოდ დამწყები პროგრამისტის შექმნილია) მაშინ თქვენი რეგექსი შეიძლება ასე გამოიყურებოდეს.

Სადაც ვეძებთ True-ს, პირველი კომპილაციის დროს ტექსტი პოულობს სასურველ შედეგს და matches მეთოდი გვიბრუნებს true-ს, Მაგრამ ყველა სხვა დანარჩენ შემთხვევაში შედეგი არის false, ავხსნათ რატომ! ჩვენი პატერნი ითხოვს ზუსტ თანხვედრას საძიებო ტექსტან, პირველ შემხვევაში ეს თანხვედრა კმაყოფილდება, მეორე შემთხვევაში ეს თანხვედრა არ კმაყოფილდება რადგან გადაწოდებული ტექსტი იწყება პატარა ბგერით, ჩვენ კი მოთხოვნა დიდ ბგერაზე გვაქ, მესამე და მეოთხე კომპილაციის დროს თანხვედრა არ გვაქ რადგან პატერნი ითხოვს რო ტექსტი უნდა იწყებოდეს დიდი ბგერით მაგრამ იწყება სიცარიელით და უნდა სრულდებოდეს e ბგერით, მაგრამ სრულდება სიცარიელით. Სიცარიელეზე გვერდის ავლს ან მათ მოძიებას მოგვიანებით მოუბრუნდებით, ახლა კი მინდა ვისაუბრო სიმბოლურ კლასებზე. Სიმბოლური კლასის დეფინირება ხდება [] ორი კვადრატული ფრჩხილით, იგივე ფრჩხილებით ჯავაში მასივის დეფინირება ხდება, (სწორედ ამას ვგულისხმობდი დასაწყისში, როცა ვამბობდი რომ, თქვენს მიერ კარგად ნაცნობი სიმბოლოები ჯავაში, სულ სხვა დანიშნულებით გამოიყენება რეგექსში), რომლის მეშვეობითაც ახდენთ არჩევანის გაკეთებას, ეს არჩევანი შეიძლება იყოს ბგერები, ციფრები ან ორივე ერთად, დაუშვათ იგივე პატერნს, რომელიც წინა ფოტოზე გამოვიყენეთ თუ შევცვლით
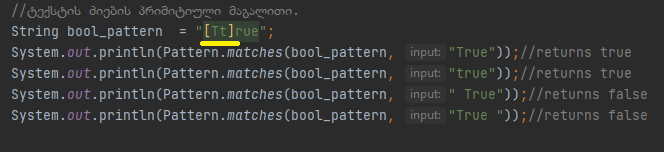
Სიმბოლური კლასით, მაშინ ჩვენ გვეძლევა არჩევანი კვადრატულ ფრჩხილებში მოქცეულ ბგერებს შორის, რეგექს ეს სინტაქსი ესმის შემდეგნაირად, სიტყვა უნდა იწყებოდეს დიდი T-თი ან პატარა t-თი და უნდა სრულდებოდეს rue-თი, შესაბამისად კომპილირების დროს პირველი ორი კომპილაცია დააბრუნებს true-ს. Რეგულარულ გამოხატულებაში სიმბოლური კლასის ამ სახით გამოყენებას მარტივი გამოყენება ქვია, თუმცა სიმბოლური კლასის მარტივად გამოყენების გარდა შესაძლებელია რამოდენიმე სხვა სახით გამოყენებაც,

Ფოტოზე ნაჩვენებ მაგალითზე ხედავთ სიმბოლური კლასის, დიაპაზონში გამოყენებას, სადაც ვამბობთ რომ გვსურს მოვიძიოთ ნებისმიერი ბგერა a-ან z-ე, პირველი კომპილაციის დროს დადებით შედეგს ვღებულობთ, სხვა ყველა დანარჩენი კომპილაციის დროს უარყოფით შედეგს ვღებულობთ, პირველი კომპილაცია რატო ამბრუნებს დადებით შედეგს ნათელია, a-ი დიაპაზონში ჯდება, მეორე კომპილაცია უარყოფით შედეგს აბრუნებს იმიტომ, რომ ჩვენი პატერნი ზუსტად ერთ ბგერას ეძებს, ჩვენ კი 2 ბგერა გვაქ, (ერთზე მეტი ბგერის ძიება როგორ უნდა მოახდინოთ ამასაც განვიხილავთ ოდენობებზე საუბრის დროს), მესამე კომპილაცია დიდი ბგერაა, ჩვენ კი პატარა ბგერა გვსურს და მეოთხე კომპილაცია საერთოდ არ არის ბგერა, შესაძლებელია დიაპაზონის გაზრდაც

Ფოტოზე ნაჩვეენებ მაგალითზე პატერნი ითხოვს, ყველა პატარა ბგერას ან ყველა დიდ ბგერას ან ყველა ციფრს ან @ სიმბოლოს ან _ სიმბოლოს, ამდენი “ან” იმიტომ დავწერე მოთხოვნებს შორის, რომ მნიშვნელოვანია იცოდეთ როგორ ხდება ინტერპრეტირება სინტაქსის ჯავას მიერ, ამაზე ვრცლად დაბლა ვისაუბრებთ, ახლა კი შეგვიძლია ვთქვათ რომ რეგექს გააჩნია ორი სახის ინტერპრეტაციის უნარი “ან ის ან ეს” სადაც რომელიმე მოთხოვნა უნდა იყოს მართებული და “ის და ეს” სადაც ორივე მოთხოვნა უნდა იყოს მართებული. ვინაიდან კომპილაციის დროს ვაწოდებთ ყველა სასურველ ბგერას, ციფრს და სიმბოლოს, შედეგი ხუთივე შემთხვევაში დადებითია. @ და _ სიმბოლოები იმიტომ გადავაწოდეთ პირდაპირ სიმბოლურ კლას, რომ მათი გამოყენება არ ხდება რეგექსის მიერ, თუმცა სურვილი რომ გვქონოდა ოკუპირებული სიმბოლოს ძიების,
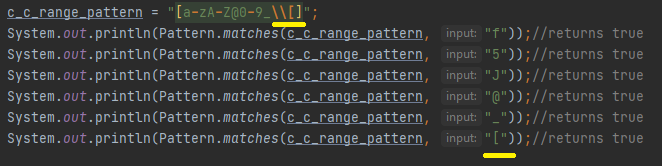
Მაშინ როგორც უნდა მოვახდინოთ სიმბოლოზე სპეციალური დანიშნულების ჩამორთმევა, მაღლა განვიხილეთ. Ამ შემხვევაში დიაპაზონში გვინდა [ ფრჩხილიც, რომელსაც ბოლო კომპილაციის დროს ვპოულობთ და ვაბრუნებთ დადებით შედეგს. Შემდეგი კლასის სახეობა არის “ერთობა”
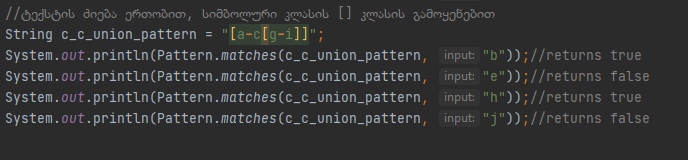
Სადაც ვახდენთ ორი სიმბოლური კლასის გაერთიანებას, პირველი ითხოვს სიმბოლოს a-ან c-ე ან მეორე ითხოვს სიმბოლოს g-ან i-ე, ყველა სხვა ბგერა დააბრუნებს მცდარ შედეგს, უფრო კარგად რო წარმოიდგინოთ ნახეთ ციფრებთან ერთობის გამოყენების მაგალითი.

Სადაც პიველი კლასი ითხოვს დიაპაზონს 3-ან 5-ე, და მეორე კლასი ითხოვს დიაპაზონს 4-ან 7-ე, როგორც ხედავთ დიაპაზონებს შორის ხდება კვეთა, 4 და 5-ს ითხოვს ორივე კლასი, ასეთი კვეთა რეგექსში სავსებით ნორმალურია. Შემდეგი კლასის სახეობა არის “კვეთა”, რომლის სინტაქსიც იმატებს & სიმბოლოს, სინტაქსის დაფაზე ეს ნიშანი იმიტომ არ მოხვდა, რომ “და” შორისდებული როგორც წესი ავტომატურად გამოიყენება ხოლმე რეგექსში და ამაზეც ვისაუბრებთ ამ ბლოგში.
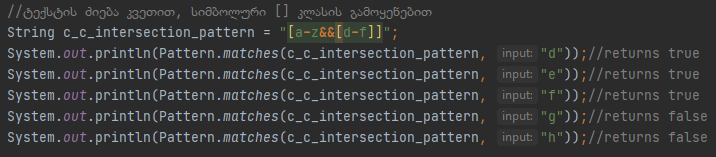
Ფოტოზე ნაჩვენებ მაგალითზე კი ვითხოვთ ყველა სიმბოლოდან მხოლოდ d-ან f-ე, კვეთის გამოყენების მაგალითი თავის თავშივე აბსურდულია, რადგან ზუსტად იგივე შედეგის მიღევა შეგვიძლია მხოლოდ [d-f]- დიაპაზონის გამოყენებით, მაშინ ჩდება კითხვა, რათ გვინდა ამ სახის კვეთის ქონა საერთოდ, ჯგუფებთან ან თუნდაც ჯგუფების გარეშე ზოგჯერ ხვდებით სიტუაციაში სადაც კვეთა სასარგებლოა, მაგალითად, წინასწარ დეფინირებულ ბერძნული კლასის გამოყენების დროს [\p{InGreek}&&\p{Ll}], რომელსაც ამ ბლოგში სავარაუდოდ არ ავხსნით და თუ ავხსნით ეს ინფორმაცია არაფრის მომცემი იქნება თქვენთვის, მსგავსი რეგულარული კლასების გამოყენების ალბათობა რეალურ პროგრამირებაში თითქმის 0-ს უდრის, მსგავს ალბათობაზე დროის დათმობის სურვილი მე პირადად არ მაქ, თუ თქვენ დაინტერესდებით ბლოგს ბოლოში ლინკს მივაბამ სადაც ჯავას ოფიციალური დოკუმენტაცია ამის შესახებ ვრცლად საუბრობს, ახლა კი გავაგრძელოთ კვეთის კიდევ ერთ ნაირსახეობაზე საუბარი, რომელსაც “გამოკლება” ქვია.

Სადაც ხედავთ ^ სიმბოლოს, როდესაცვ ამ სიმბოლოს კლასის შიგნით გამოყენება ხდება, მაშინ ის უარყოფას ნიშნავს, კლასის გარეთ რა დანიშნულება აქვს მოგვიანებით გაიგებთ.ამ სიმბოლოს მეშვეობით ვაკლებთ ყველა სიმბოლოს, იმ სიმბოლოებს, რომელსაც ვეძებთ, ფოტოზე ნაჩვენებ მაგალითზე გვინდა ყველა სიმბოლო a, b და c-ს გამოკლებით. Მისი წინამორბედი კვეთისგან განსხვავებით, კლასის ეს სახეობა საკმაოდ ხშირად გამოიყენება ყოველდღიურ პროგრამირებაში. Ამ ეტაპისთვის ვიცით რა არის სიმბოლური კლასი და რომელი სიმბოლოების გამოყენება ხდება ამ კლასში, თუმცა ჯავაში ნაჩვენები მაგალითების წინასწარ დეფინირებული კლასები არსებობს. Რომლის დაფაც შემდეგნაირად გამოიყურება
Ვნახოთ დაფაზე ნაჩვენები პრედეფინირებული კლასები, მის აღწერასთან მოდის თუ არა თანხვედრაში.

Ნებისმიერ სიმბოლოსთან თანხვედრა მცდარია escape sequence \n და \r-ის შემთხვევაში, სხვა escape sequence-ის შემთხვევაში მართებულია, რის შემდეგაც ხედავთ გაგრძელებას, სადაც ვეძებთ ნებისმიერ სიტყვას, რომელიც მთავრდება ava-ზე, ხუთივე მაგალითი აბრუნებს დადებით შედეგს. Პრედეფინირებული \d ეძებს მხოლოდ ციფრებს

\D კი ყველაფერს ციფრების გარდა
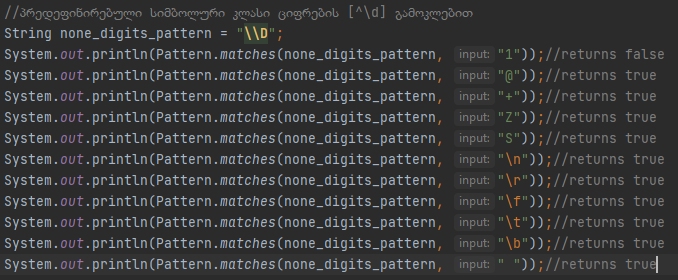
Ფოტოზე ნაჩვენებ მაგალითზე ვალიდაციას გადის ნებისმიერი სიმბოლო, ბგერა, მეტა-სიმბოლო, ცარიელი ადგილი თუ escape sequence ციფრის გარდა. Ზუსტად იგივე პრინციპით მუშაობს პრედეფინირებული კლასი ბგერების შემთხვევაშიც,

\w-ის ვალიდაციას გადის ყველა სიმბოლო, დიაპაზონში [a-zA-Z0-9_] და \W-ის შემთხვევაში ვალიდაციას გადის ნებისმიერი რამ [^\w]-ის გარდა

Მსგავსად მუშაობს სიმბოლური კლასი ცარიელი ადგილების ვალიდაციისთვის
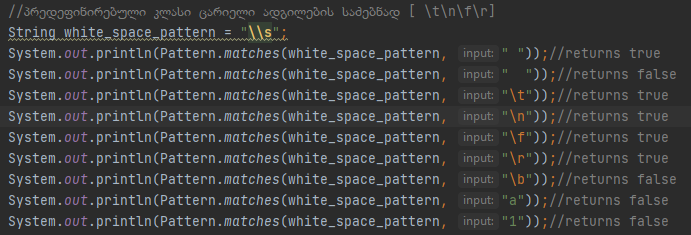
Სადაც \s პოულობს ყველა სიცარიელეს და \S პოულობს ყველაფერს სიცარიელის გარდა
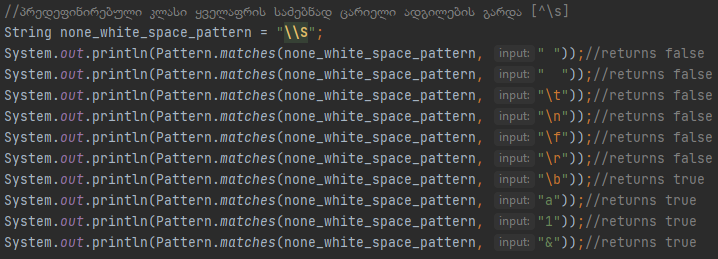
Ამით სიმბოლურ კლასებზე და პრედეფინირებულ სიმბოლურ კლასებზე საუბარს მოვრჩით, ყველა მაგალითი რომელიც აქამდე ვნახეთ ვალიდაციას ატარებს მხოლოდ ერთ ბგერას, ციფრს, სიმბოლოს, სიცარიელეს თუ ნებისმიერ სხვა რამეს, მაგრამ ტექსტში როგორც წესი ერთი სიმბოლო არ გვაქ ხოლმე, ის უამრავი სიმბოლოს ერთობაა, find მეთოდი ერთ სიმბოლოზე მეტს ეძებს, მაგრამ მაგალითებისთვის matches მეთოდს ვიყენებთ და გამოვიყენებთ ბოლომდე, სანამ ჯავაში არსებულ რეგექსის კლასებს არ ვნახავთ, სწორედ ამიტომ უნდა ვისაუბროთ რაოდენობრივ მაჩვენებლებზე, რომლის მეშვეობითაც ვამბობთ რამდენი სიმბოლოს მოძიება გვინდა. Რაოდენობრივ მაჩვენებლებთან მუშაობისთვის შემდეგი მეტა-სიმბოლოებია გამოყოფილი
Რომელთა გამოყენებაც იყოფა 3 ქვე-კადეგორიად
Სტანდარტულად რაოდენობრივი მაჩვენებელი ხარბად მუშაობს, ამას პირველ კოლონაში ხედავთ, ჯერ ჩვეულებრივ რაოდენობრივ მაგალითებს ვნახავთ და შემდეგ განვიხილავთ ქვე კატეგორიებს ან მაშინ სადაც მათი განხილვა რელევანტური იქნება. Მაშ ასე იმისათვის, რომ მოვიძიოთ ელემენტი 0-ჯერ ან 1-ელ, ვიყენებთ “?” სიმბოლოს

Ნაჩვენებ მაგალითზე პირველი ორი ტექსტი გადის ვალიდაციას, რადგან პირველ შემთხვევაში გვაქ ერთი სიმბოლო დამეორე შემთხვევაში გვაქ 0 სიმბოლო, მესამე შემთხვევაში კი გვაქ 1-ზე მეტი სიმბოლო, რაც რა თქმა უნდა მცდარ შედეგს გვიბრუნებს. Შემდეგი რაოდენობრივი მაჩვენებელი ზუსტად იგივეს აკეთებს რასაც “?” მაჩვენებელი, უბრალოდ არ გვაქ ზედა ზღვარი.
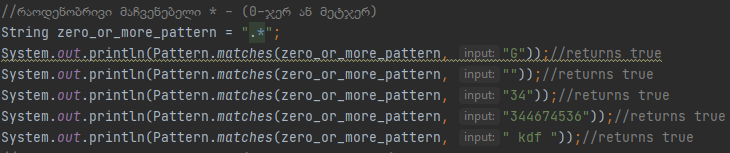
Ნაჩვენებ მაგალითზე ვალიდაციას ვატარებთ ნებისმიერ სიმბოლოს, თუ ის გვხვდება 0-ჯერ ან მეტჯერ, შესაბამისად ყველა ვალიდაცია აბრუნებს დადებით შედეგს, შემდეგი მაგალითი გავს “*” რაოდენობრივ მაჩვენებელს, უბრალოდ ქვედა საზღვარი იწყენაბ ერთიდან.
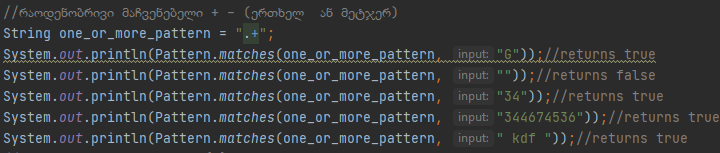
Შესაბამისად მეორე ვალიდაციის გარდა, ყველა სხვა ვალიდაცია აბრუნებს დადებით შედეგს, შემდეგი მაგალითი მუშაობს ზუსტ რაოდენობასთან.

Გვინდა ნებისმიერი 3 სიმბოლო და ვატარებთ ვალიდაციას 2,3 და 4 სიმბოლოს, სამი ვალიდაციიდან მეორე აბრუნებს დადებით შედეგს, შემდეგ მაგალითზე ვახდენთ მინიმალური ზღვარის დაწესებას.

Ვითხოვთ, რომ მინიმმალური ოდენობა სიმბოლოსი უნდა იყოს სამი და მაქსიმალური ოდენობა იმდენი რამდენიც იქნება. Შესაბამისად პირველი ვალიდაციის გარდა ყველა სხვა დანარჩენი აბრუნებს დადებით შედეგს, რადგან პირველი ტექსტის სიდიდე 2 ელემენტს უდრის. Ბოლო რაოდენობრივი მაჩვენებელი არის, მინიმალური და მაქსიმალური ოდენობების დეფინირება,
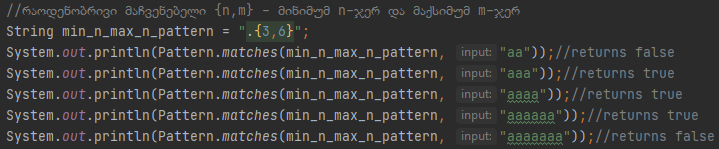
Სადაც ვამბობბთ რომ ნებისმიერი სიმბოლო უნდა იყოს მინიმუმ 3 და მაქსიმუმ 6 სიმბოლოს სიდიდის, პირველი ვალიდაცია 2 სიმბოლოა ბოლო ვალიდაცია კი 7 სიმბოლო, შესაბამისად ამ ორ შემთხვევაში ვიღებთ მცდარ შედეგს, დანარჩენი შემთხვევებისა დადებით პასუხს გვიბრუნებს, იმიტომ რო 3-ან 6 სიმბოლოს ოდენობაში ვეტევით. Განვიხილოთ რაოდენობრივი მაჩვენებლების კატეგორიები, როგორც ვახსენე სტანდარტულაფ რაოდენობრივი მაჩვენებელი ხარბად(Greedy) მუშაობს, მაგრამ ხარბ რაოდენობრივ მაჩვენებელს თუ დავამატებთ ? სიმბოლოს მაშინ შედეგად ვიღებთ ზარმაც (Reluctant) რაოდენობრივ მაჩვენებელს ან თუ დავამატებთ + სიმბოლოს მაშინ შედეგად ვიღებთ Possessive (ქართულად როგორ არის არ ვიცი) რაოდენობრივ მაჩვენებელს. Იმისათვის რომ გავიგოთ როგორ მუშაობენ რაოდენობრივი მაჩვენებლების ნაირსახეობები უნდა გავიგოთ, როგორ მუშაობს თითოეული მათგანი და როგორ გებულობს მოთხოვნას, ამ კონკრეტულ შემთხვევაში ჯავას მიერ შემოთავაზებული რეგექსი. Მაშ ასე მთავარი რამ რაც უნდა ვიცოდეთ მაჩვენებლებზე არის ის რომ, ხარბი რაოდენობირივი მაჩვენებელი აკეთებს ზუსტად იმას რის საპატივცემლოდაც ატარებს სახელს, ეძებს ტექსტს ხარბად, სასურველი ტექსტის მოძიების შემდეგ აგრძელებს ძებნას და აბრუნებს ყველაზე დიდ შესაძლო ტექსტს, ზარმაცი რაოდენობრივი მაჩვენებელი აკეთებს ზუსტად იმას რის საპატივცემლოდაც ატარებს სახელს, ეძებს სასურველ ტექსტს და აბრუნებს ყველაზე პატარა შესაძლო ტექსტს, Possessive რაოდენობირივ მაჩვენებელი კი მუშაობს ზუსტად ისე როგორც ხარბი, ერთი განსხვავებით ის არ ასრულებს უკუსვლებს ტექსტში, ალბათ ამ ეტაპზე გაუგებარია რას ვგულისხმობ, მაგრამ მაგალითებზე უფრო გასაგები იქნება გახდება. Დავიწყოთ ხარბი რაოდენობრივი მაჩვენებლით, გავაგრძელებთ ზარმაცი მაჩვენებლით და დავასრულებთ Possessive მაჩვენებლით, ბოლოს კი ავხსნით რა სხვაობაა მათ შორის და რატო მუშაობენ ისე როგორც მუშაობენ. Რომ დავიწყოთ მაგალითების ჩვენება, ჯერ მოვახდენ ერთი მეთოდის დეფინირებას, რომელსაც სამივე კატეგორიის განხილვისთვის გამოვიყენებთ.

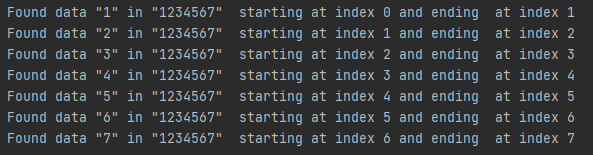
Სადაც წინა მაგალითებისგან განსხვავებით ხედავთ როგორ ხდება რეგექს პატერნის კომპილირება და შემდეგ find მეთოდის მიერ ამ პატერნის ძიება გადაწოდებულ ტექსტში, find მეთოდი matches მეთოდისგან განსხვავებით კითხულობს ყველა სიმბოლოს გადაწოდებულ ტექსტში, რაც ნიშნავს იმას რომ, თუ matches მეთოდის გამოყენების დროს ვითხოვდით [0-9] ნებისმიერს ციფრს და სასურველი შედეგი დგებოდა მხოლოდ ერთი ციფრის მოძიების შემთხვევაში, find მეთოდის შემთხვევაში

Რაოდენობრივი მაჩვენებლის გამოყენების გარეშე შესაძლებელია მთლიანი ტექსტის წაკითხვა მოხდეს, პირველი სიმბოლოდან ბოლო სიმბოლომდე. Რაც შესაბამის შედეგსაც აბრუნებს
Ყველაფერი გვაქ მაგალითებისთვის, დროა გავიგოთ როგორ მუშაობს ხარბი რაოდენობრივი მაჩვენებლი.

Რა თქმა უნდა ხარბი მაჩვენებლებიდან მხოლოდ ერთს გამოვიყენებთ, რომ მაგალითები არ გადაიტვირთოს, ამ შემთხვევაში ვიმუშავებთ * 0-ჯერ ან მეტჯერ მაჩვენებლით, მუშაობის პრინციპი სხვა მაჩვენებლბესაც იგივე ან დაახლოებით იგივე აქვთ. Ვნახოთ ძიების შედეგი და განვიხილოთ რა მოხდა.
Როგორც ხედავთ მოხდა java is good, i like java! Ტექსტის მოძიება Pr lang java is good, i like java!-ში, პირველი რაც რეგექსმა ხარბი მაჩვენებლით მოიძია არის მთლიანი ტექსტი Pr lang java is good, i like java!, რაც არ მოდის თანხვედრაში ჩვენ მოთხოვნასთან, რის შემდეგადაც დაიწყო თითო სიმბოლით უკუსვლა ბოლო სიმბოლოდან, ანუ იპოვა ! ნიშანი რაც არ აკმაყოფილებს მოთხოვნას, სასურველი ტექსტი j-ი იწყება და ava-ი სრულდება რის შემდეგაც ნებისმიერი ოდენობის სიმბოლო შეიძლება იდგეს, ვერ მივაგენით j-ს ბოლო სიმბოლოზე, კიდევ ერთი ნაბიჯით განაგრძო უკუსვლა და იპოვა a!, რაც ისევ არ აკმაყოფილებს ჩვენ მოთხოვნას, შესაბამისად ვაგრძელებთ უკუსვლით ძებნას, va!, შემდეგ ava! Და ბოლოს java! Რაც აკმაყოფილებს ჩვენს მოთხოვნას, ვინაიდან ვიყენებთ ხარბ რაოდენობრივ მაჩვენებელს, რეგექსი არ ჩერდება ნაპოვნ შედეგზე, ხარბი იმიტომ არის რომ უნდა მოიძიოს ყველაზე დიდი შესაძლო ტექსტი, ტექსტში, რის გამოც აგრძელებს ძიებას, ზუსტად იგივე პრინციპით, ერთი სიმბოლოთი მოყვება უკნიდან და პოულობს მეორე java-ს, რის შემდეგაც აგრძელებს ძიებას ბოლო სიმბოლომდე, ანუ კითხულობს P-ს, ხედავს რომ სხვა java არ გვაქ ტექსტში და აბრუნებს ყველაზე დიდ შესაძლო რეზულტატს რაც ამ შემთხვევაში არის java is good, i like java! Მგონი პრინციპი ხარბად მუშაობის გასაგებია, ახსნიდან რაც უნდა დაიმახსოვროთ არის ის რომ, ხარბი რაოდენობრივი მაჩვენებელი მუშაობს უკუსვლით და ცდილობს დააბრუნოს ყველაზე დიდი შესაძლო რეზულტატი ტექსტიდან. Სხვა დეტალების ცოდნა არც ისე მნიშვნელოვანია, მაგალითად რას აკეთებს პირველ ცდაზე, მთლიან ტექსტს კითხულობს, კონკრეტულ ინდექსზე კითხულობს თუ დახტის ინდექსებზე არის მეათასე ხარისხოვანი, მთავარი არის ეს ორი რამ, უკუსვლით ძიება და ყველა დიდი შესაძლო რეზულტატი ტექსტიდან. Თუ ნაჩვენებ მაგალითს დავამატებთ ? სიმბოლოს ხარბი რაოდენობირივი მაჩვენებელი გადაკეთდება,
ზარმაც (Reluctant) რაოდენობრივ მაჩვენებლად და მისი მუშაობის პრინციპი სრულიად საპირისპიროა ხარბისგან, ზარმაცი მუშაობას იწყებს წინიდან, ანუ ტექსტის დასაწყისიდან და კითხულობს თითო ბგერას თითო ჯერზე, რის შემდეგადაც აბრუნებს ყველაზე პატარა შესაძლო რეზულტატს, ბოლოს კი კითხულობს მთლიან ტექსტს, ფოტოზე ნაჩვენებ მაგალითზე .*? Გადმოვიტანე ჯავას წინ, რომ მაგალითი უფრო თვალსაჩინო იყოს, რას ვგულისხმობ მიხვდებით, ეს პატერნი აბრუნებს


Ამ შედეგს, დასაწყისშივე იგრძნობა სხვაობა, ხარბი რაოდენობრივი მაჩვენებელი აბრუნებს ერთ შედეგს, ზარმაცი კი აბრუნებს ორ შედეგს, განვიხილოთ რატო ხდება ასე, როგორც მაღლა ვახსენე ზარმაცი მაჩვენებელი ძიებას იწყებს წინიდან, ამ შემთხვევაში ჩვენი ძიება იწყება P ბგერიდან, შემდეგ მოსდევს r, l, a და ა.შ, ძიება გრძელდება მანამ სანამ ვიპოვით java-ს, როგორც კი ვიპოვით სასურველ ტექსტს და ის პატერნთან მოდის თანხვედრაში რეგექს ამის მერე არაფერი აინტერესებს, ის გვიბრუნებს ყველაზე პატარა შესაძლო ტექსტურ რეზულტატს, Pr lang java-ს ამ შემთხვევაში, ამის შემდეგ, find ბრუნდება აგრძელებს ძიებას და აბრუნებს ისევ ყველაზე პატარა შესაძლო რეზულტატს, ყველაზე თვალსაჩინო ზარმაცი მაჩვენებლის ქმედება ხდება მაშინ როცა სასურველი ტექსტი მეორდება საძიებო ტექსტში.
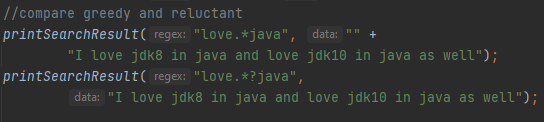
Ფოტოზე ნაჩვენებ მაგალითზე ორივეს, ხარბს და ზარმაცს რაოდენობრივ მაჩვენებლებს ხედავთ.

Ეს კი არის მათ მიერ დაბრუნებული შედეგი, წითლად ხასგასმული რეზულტატი არის ხარბი რაოდენობირივი მაჩვენებლის მიერ დაბრუნებული, მწვანედ ხასგამული ველები კი არის ზარმაცი რაოდენობირივი მაჩვენებლის მიერ დაბრუნებული, ხარბი ეძებს ყველაზე დიდ შესაძლო რეზულტატს ტექსტში, პირველი ცდილობს მთლიანი ტექსტის დამუშავებას და შემდეგ მოყვება ბოლო ბგერიდან უკუსვლით, ზრმაცი ძიებას იწყებს წინიდან, თუ პოულობს სასურველ შედეგს ეგრევე აბრუნებს რეზულტატს, როცა ასრულებს ოპერაციას ცდილობს მთლიანი ტექსტის დამუშავებას. Შემდეგი რაოდენობირვი მაჩვენებელი არის Possessive, რომელიც ყველაზე ნაკლებად გამოყნებადი რაოდენობირივი მაჩვენებელია, მუშაობის პრინციპით ძალიან გავს ხარბ რაოდენობრივ მაჩვენებელს, მაგრამ მას არ გააჩნია უკუსვლის ფუნქცია, ის ყოველთვის ამუშავებს მთლიან ტექსტს, მხოლოდ ერთხელ. Possessive რაოდენობირივი მაჩვენებელი რომ გამოიყენოთ საკმარისია + სიმბოლო დაამატოთ ხარბ რაოდენობრივ მაჩვენებელს

Ფოტოზე ნაჩვენებ მაგალითზე ვითხოვთ java-ს რომლის შემდეგაც ნებისმიერი ოდენობის სიმბოლო შეიძლება გვექნეს, რეზულტატი ამ ძიების არის

Ზუსტად იგივე როგორიც დაგვიბრუნა ხარბმა, თუმცა მისი მუშაობის პრინციპს უკეთ რო ჩაწვდეთ, შევადაროთ დანარჩენ ორ მაჩვენებელს.
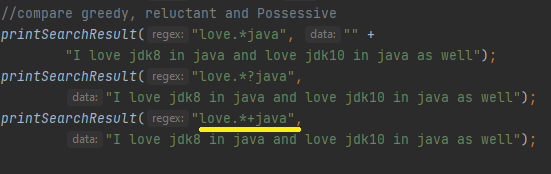
Ყვითლად ხაზგასმული პატერნი არის Possessive რაოდენობირივ მაჩვენებელი, სამივე ოპერაცია კი აბრუნებს შემდეგ შედეგს,

Სადაც წითელ ჩარჩოში არის ხარბი მაჩვენებლის შედეგი, ყვითელ ჩარჩოში არის ზარმაცი მაჩვენებლის შედეგი და ლურჯ ჩარჩოში არის Possessive მაჩვენებლის შედეგი, ხედავთ რო Possessive მაჩვენებელმა სასურველი შედეგი ვერ მოიძია ტექსტში, ავხსნათ რატომ! ჩვენი პატერნის თანახმად ტექსტი უნდა იწყებოდეს love სიტყვით გრძელდებოდეს ნებისმიერი ოდენობის სიმბოლოთი და სრულდებოდეს java-თი, Possessive მაჩვენებელმა იპოვა love ტექსტი, რის შემდეგაც წაიკითხა ყველა დარჩენილი სიმბოლო , ბოლო სიმბოლო იყო l, well სიტყვიდან, რის შემდეგაც ვერ ნახა java და დააბრუნა რეზულტატი სადაც ამბობს რო ვერ მოახერხა ტექსტის მოძიება, ვინაიდან ეს მაჩვენებელი კითხულობს მთლიან ტექსტ მხოლოდ ერთხელ და არ გააჩნია უკუსვლის ფუნქცია, შედეგი სავსებით ლოგიკურია. Სულ ეს იყო რისი თქმაც შეიძლებოდა რაოდენობრივ მაჩვენებლებზე, იმედია ლოგიკა და მატი მოქმედების პრინციპები გასაგებია. Უფრო რო გაირღმაოთ ცოდნა შეგიძლიათ

Მსგავსი პატერნი შექმნათ ყველა არსებულ ?,*,+,{n},{n.}{n,m} რაოდენობირვ მაჩვენებელზე, იმუშაოთ Greedy, Reluctant, Possessive კატეგორიებით და ნახოთ როგორ მოქმედებენ ისინი, 1-2 საათის თამაშით საფუძვლიანი ცოდნა გექნებათ რაოდენობივ მაჩვენებლებზე. Ამ ეტაპზე ვიცით სიმბოლური კლასები და რაოდენობრივი მაჩვენებლები, ვერ წარმოიდგენთ მაგრამ მხოლოდ აქამდე თქმულის ცოდნაც კი საკმაოდ დიდ გასაქანს მოგცემთ რეალურ პროგრამირებაში, იმიტომ რო იცით როგორ მოიძიოთ ნებისმიერი სიმბოლო და იცით რა ოდენობით გსურთ ესა თუ ის სიმბოლო. Ცოდნა კიდევ უფრო რო გაიმყაროთ შეგიძლიათ “სად” კითხვასაც გავცეთ პასუხი, ანუ სად გვინდა ტექსტში ინფორმაციის მოძიება? Ამისთვის არსებობს საზღვრები (Boundaries) და მისი დაფა ასე გამოიყურება
Ყველა საზღვარს აქვს აღწერა, თუ რას აკეთებს, მაგრამ დარწმუნებული ვარ ეგ აღწერა არაფრის მთქმელი არ არის საერთოდ, რამე რო თქვას საჭიროა მაგალითები ვნახოთ, სადაც უფრო კარგად შეგვექმნება წარმოდგენა სიმბოლოებზე და აღწერაც ბევრად გასაგები გახდება. Დავიწყოთ პირველი ^ სიმბოლოდან, ჯავას ოფიციალური დოკუმენტაცია ამბობს, რომ ეს სიმბოლო ველის დასაწყისია თუმცა პრქკტიკაში ის უბრალოდ ტექსტის დასაწყისია და არა ველის. Მაგალითად
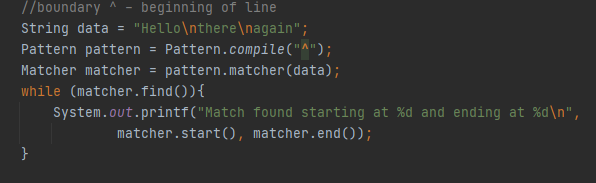
Თუ ^ ველის დასაწყისია და არა სიტყვის, მაშინ ფოტოზე ნაჩვენებ ტექსტში ველი 3 ადგილზე იწყება, H,t და a-ზე, შესაბამისად კონზოლში შედეგად უნდა მივიღოთ, 0-0, 6-6 და 12-12 ინდექსები, სამაგიეროდ კი ვღებულობთ
Რაც ნიშნავს იმას, რომ ველის დასაწყისიდან ძიებას აშკარად არ ვითხოთ, არამედ სიტყვის დასდაწყისიდან. Ვნახოთ იგივე პატერნის უფრო პრაკტიკული მაგალითი.
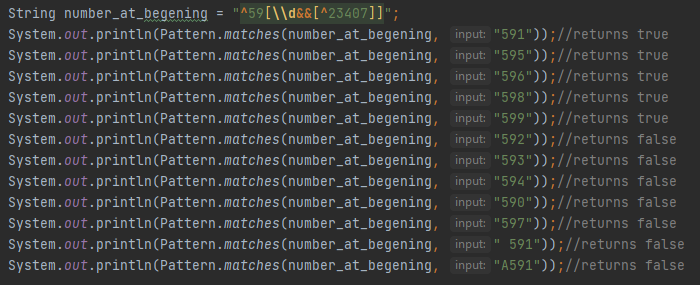
Სადაც ვახდენთ მაგთიკომის პრეფიქსის ვალიდაციას, ვითხოვთ რომ ტექსტი უნდა იწყებოდეს 59-ით მას უნდა მოყვებოდეს ნებისმიერი ციფრი \\d 0-ან 9-ე, 23407-ის გამოკლებით, როდესაც ^ სიმბოლოს ვიყენებთ კლასის გარეთ ის ველის დასაწყის ნიშნავს როცა ვიყენებთ კლასში უარყოფას. Შევეცადე პატერნში ყველაფერი გამომეყენებინა რაზეც აქამდე ვისაუბრეთ,შედეგებს უკნიდან მოვყვეთ, ბოლო ტექსტი იწყება ბგერით, შემდეგი ტექსტი იწყება სიცარიელით და შემდეგი 5 ტექსტი შეიცავს იმ ციფრებს რომელიც არ უნდა შეგვხვდეს მაგტიკომის პრეფიქსში, ყველა სხვა ცდა აბრუნებს დადებით შედეგს. Შემდეგი სიმბოლო ჩვენი დაფიდან არის $ რომელიც თქვენთვის სასურველი ინფორმაციის ქონას ითხოვს ტექსტის ბოლოში, თუ იგივე მაგტიკომის ნომრის ვალიდაციას მივყვებით
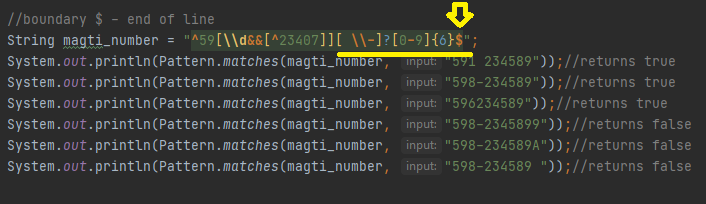
Მაშინ შეგვიძლია მოვითხოვოთ რომ ტექსტი უნდა სრულდებოდეს 6 ნებისმიერი ციფრით. Ყვითლად ხასგასმული ნაწილი არის ახალი პატერნი, მის წინ მდგომი პატერნი იგივეა, რაც წინა მაგალითზე ვნახეთ, საერთო ჯამში პატერნი ითხვს რო პრეფიქსი უნდა იწყებოდეს 59 რის შემდეგაც შეიძლება გვექნეს ნებისმიერი ციფრი 23407-ის გამოკლებით, რომელსაც შეიძლება მოსდევდეს სიცარიელე ან დეფისი ან შეიძლება არ მოსდევდეს, რადგან ? რაოდენობრივ მაჩვენებელს ვიყენებთ, რომელიც 0-ს ან 1-ს ნიშნავს და ტექსტი უნდა სრულდებოდეს ნებისმიერი 6 ციფრით 0-ან 9-ე. Პირველი სამი მაგალითი ამ მოთხოვნას აკმაყოფილებს, ბოლო სამ მაგალითზე კი ტექსტი სრულდება, 7 ციფრით, ბგერით და სიცარიელით, შესაბამისად რეზულტატი გვეუბნება, რომ მოთხოვნა ვერ დაკმაყოფილდა. Თუ ეს მაგალითი ზედმეტად კომპლექსრუია შეგიძლიათ შემდეგი მაგალითიც გააკეთოთ,

Სადაც უბრალოდ ვითხოვთ ტექსტის com-ზე დასრულებას. Მას წინ ნებისმიერი ერთი ან მეტი სიმბოლო შეიძლება უძღვოდეს. Შემდეგი საზღვარი არის \b რომელის სიტყვის საზღვარია, მისი დასაწყისი ან დასასრული. Ის სიტყვას ეძებს \w და \W-ს საზღვარზე უფრო \w-ს ჩარჩოებში. Მაგალითად
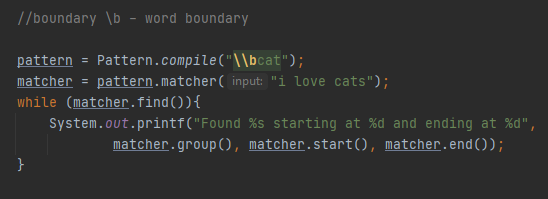
\\bcat ეძებს სიტყვას რომელიც იწყება cat-ზე ან
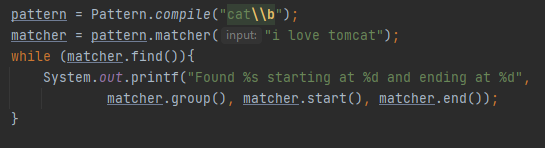
Cat\\b ეძებს სიტყვას რომელიც სრულდება cat-ზე ან შეგიძლია ზუსტად cat მოვიძიოთ \\bcat\\b პატერნით,

Რომელიც ამბობს რომ სიტყვა უნდა იწყებოდეს და მთავრდებოდეს cat-ით, მაგრამ რა ხდება თუ cat არ გვაქ სიტყვის დასაწყისში ან ბოლოში და ის უფრო დიდი სიტყვის ნაწილია? Წინა მაგალითზე cat\\b სიტყვა tomcat-ის ნაწილია, მისი კომპილაცია

Პოულობს cat-ს, მაგრამ მოძებნის იგივე საზღვარი სიტყვა uncommunicative-ში cat-ს, პასუხი არის არა, იმისათვის რომ მსგავს სიტყვასი cat მოვძებნოთ უნდა გამოვიყენოთ უსიტყვო საზღვარი \\B რომლის მოვალეობაც არის მოძებნოს სასურველი სიტყვა უფრო დიდ სიტყვაში.
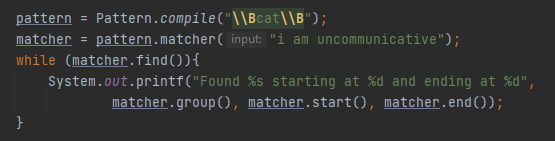
Ხშირად შეხვდებით ამ ორი საზღვრის ერთად გამოყენებასაც, მაგალითად.

Ფოტოზე ნაჩვენებ მაგალითზე ვითხოვთ, რომ სიტყვა აუცილებლადუნდა იწყებოდეს cat-ით და ის აუცილებლად უნდა იყოს უფრო დიდი სიტყვის ნაწილი, ამ შემთხვევაში cathedral-ის. Შემდეგი ორი საზღვარი ამოწმებს ტექსტი იწყება თუ მთავრდება სასურვილი მონაცემებით. \A ამოწმებს იწყება თუ არა ტექსტი სასურველი მონაცემებით.

Ალეტრნატიულად იგივე ოპერაციას ^-ც ასრულებს, რომელიც უკვე ნახეთ და \z ამოწმებს სრულდერბა თუ არა ტექსტი სასურველი ტექსტით,

Ალტერნატიულად იგივე ოპერაციას $-ც ასრულებს, ბოლო მაგალითზე ხედავთ, რომ ტექსტი სრულდება ველის გამყოფით (ტერმინატორით - \n), ვინაიდან \z ველის გამყოპფის კონსუმაციას არ ახდენს, შედეგი არის მცდარი, თუმცა თუ სურვილი გაქვთ მთლიანი დაბოლოება ტერმინატორებით წაიკითხოთ \z-ს მაგივრად \Z შეგიძლიათ გამოიყენოთ,

Მაგრამ შედეგი იდენტურია, იქ სადაც \Z-ს ტერმინატორებიც უნდა წაეკითხა, არ წაიკითხა და დააბრუნა მცდარი შედეგი, ვინაიდან \A \z და \Z მუშაობენ მთლიან ტექსტთან და არა ტექსტან რომელიც ტერმინატორზე მთავდრება, matches-ს მეთოდის მიერ დამუშავებული ტექსტი რეგექსისთვის არ ითვლება სრულ ტექსტად, მარტივად რომ ვთქვათ არ თვლის რომ მოახდინა კონსუმაცია მთლიანი იფორმაციის, რომ შეძლოს კონსუმაცია ტექსტის უნდა გამოვიყენოთ find მეთოდი,

Რის შემდეგაც მივიღებთ სასურველ შედეგს, ან შეგვიძლია matches-ს მეთოდი გამოვიყენოთ და მას გადავაწოდოთ

Სასურველი ტერმინატორი, რაც დააკმაყოფილებს ჩვენს მოთხოვნას. Მოკლე მონახაზი გავაკეთოთ, ^ ტექსტს პოულობს ველის დასაწყისში, მაგრამ ^ da \A ზუსტად ერთნაირად მუშაობს, მანამ სანამ რეგექს არ ეტყვი რო ტექსტს მრავალ ველზე ეძებ.
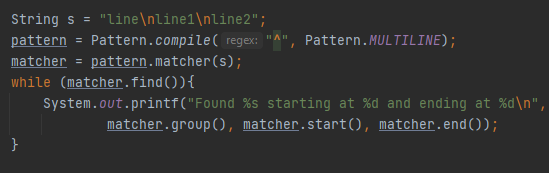
Რაც არც ისე თამამად მოდის თანხვედრაში დოკუმენტაციის მიერ ნათქვამ დეფინიციასთან, თუ ^ ტექსტს ეძებს მრავალ ველზე რეგექსი მრავალი ველის ჩართვის გარეშეც უნდა ხვდებოდეს რო ტექსტი შეიცავს ტერმინატორებს. $ და \z შესაბამისად ტექსტს ეძებენ ველის და მთლიანი ტექსტის ბოლოში, ორივესთვის მონაცემები სრულდება იქ სადაც იწყება ტერმინატორი. Მაგალითად Zoro\n თუა ბოლო მონაცემი ძიება დასრულდება o-ს მერე ექსკლუზიურად, თუ სურვილი გვაქ რო ძიება გაგრძელდეს შეგვიძლია \Z გამოვიყენოთ და მოვახდინოთ მთლიანი ტექსტის (ტერმინატორების) კონსუმაცია. Ბოლო საზღვარი, რომელზეც ვისაუბრებთ არის \G რაც ნიშნავს წინა დადებითი შედეგის ბოლოში.

Ამ შემთხვევასი წინა დადებითი შედეგი cat არის და მის ბოლოში ვპოულობთ სიტყვა cat-ს ისევ. Cat cat ამ სახით რომ დაგვეწერა, მოვძებნიდით მხოლოდ პირველ Cat-ს რადგან \G პირველ ცდაზე ზუსტად ისე მუშაობს როგორც \A, პირველი ცდის მერე კი ყველა დადებითი შედეგის ბოლოში აგრძელებს მუშაობას, ასეთი სახით ნაჩვენები მაგალითი დიდად ვერ შეგიქმნით წარმოდგენას თუ სად შეიძლება ამ საზღვრის გამოყენება, მაგრამ თუ ინტერესი გაგიჩდათ, შეგიძლიათ პოზიტიური უკუხედვის მაგალითი მოიძიოთ ინტერნეტში, რომელიც ჯგუფების ერთ-ერთი სახეობა. ჯგუფები რეგექსში არის საშუალება მოვახდინოთ დაჯგუფება მონაცემების ერთ ან რამოდენიმე ჯგუფში, რომელზეც წვდომა გვექნება ინდექსის ან სახელის მეშვეობით.
Მაგალითად simple+ ეძებს simpl-ს + e-ს, რომელიც ერთხელ ან მეტჯერ უნდა შეგვხვდეს, თუ ტექსტში simple-ს მოძებნა გვინდა რომელიც მეორდება მაშინ რას ვაკეთებთ? Შეგვიძლია სიმბოლური კლასი გამოვიყენოთ და [simple]+ მოვძებნოთ, მაგრამ მოძებნის რო ეს კლასი სასურველ მონაცემეს? Რა თქმა უნდა მოძებნის, მაგრამ რას მოძებნის კიდევ? s-ს ან i-ს ან m-ს ან p-ს ან l-ს ან e-ს ხო ?

Კი, რადგან ამ სახით სასურველი მონაცემის ძიება დააბრუნებს

Ამ შედეგს, სადაც ვხედავთ რომ simple-ის გარდა პატერნმა მონახა ყველა ის ბგერა ან ბგერათა ერთობა, რომელიც ტექსტში გვხვდება, როგორ შეიძლება რო სასურველი მონაცემი მოვნახოთ ზუსტად?
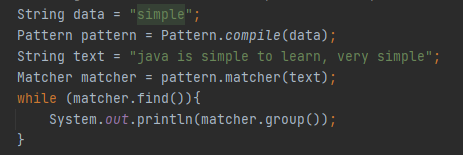
Ამ სახით პატერნი მონახავს ზუსტად იმ ტექსტს, რომელიც გვჭირდება რადგან მთლიანი პატერნი, როგორი მეტა სიმბოლოებითაც არ უნდა იყოს ის დეფინირებული ყოველთვის არის ჯგუფი ნომერი 0, რაც ნიშნავს იმას რომ არ აქვს მნიშვნელობა მოახდნთ თუ არა თქვენ ჯგუფის დეფინირებას, მისი დეფინირება ავტომატურად ხდება ყველა შემთხვევაში. Იმისათვის რომ მოახდინოთ სასურველი ჯგუფის დეფინირება უნდა გამოიყენოთ () მრგვალი ფრჩხილები. Ნებისმიერ პატერნს რომელსაც მოათავსებთ ამ ჯგუფში რეგექსის მიერ აღქმული იქნება როგორც ერთობა, იგივე მაგალითს რო დაუბრუნდეთ

Და მოვათავსოთ simple ტექსტი ()-მრგვალ ფრჩხილებში, რეგექსი მას აღიქვამს როგორც ერთ სიტყვას და არა ბგერათა ერთობას, ფოტოზე ხედავთ რო ვიძახებთ matcher.group(1) ჯგუფ ნომერ ერთს, როდესაც ვიყენებთ ჯგუფებს, ამ მონაცემების მეხსიერებაში მოთავსება ხდება, რათა მოგვიანებით შევძლოთ ინდექსის ან სახელის მეშვებოთ მათი მოძიება. Როგორც უკვე ვთქვი ნებისმიერი პატერნი არის ჯგუფი ნომერი 0, შესაბამისად როდესაც ვიყენებთ პირდაპირ ჯგუფს ინდექსირება იწყება 1-ან, შესაძლებელია იმდენი ჯგუფი იქონიოთ რამდენიც გსურთ, ისევე როგორც შესაძლებელია ჯგუფების ერთმანეთში ჩაბუდება.

Ფოტოზე ნაჩვენებ მაგალითზე გვაქ 4 ჯგუფი, პლიუს ჯგუფი ნომერი 0. ჯგუფებს გააჩნიათ უკუკავშირის უნარი (Backreference) მაგალითად

Გვაქ ჯგუფი ნომერი 1 სადაც ვითხოვთ 2 სიმბოლოს, იმისათვის რომ ზუსტად იგივე ორი სიმბოლო მეხსიერებიდან ხელახლა გამოვიძახოთ არ არის ახალი ინდენტური ჯგუფის შექმნა საჭირო, საკმარისია არსებულ ჯგუფთან მოვახდინოთ უკუკავშირი, ამ შემთხვევაში გვაქ 1 ჯგუფი, შესაბამისად ვახდენთ მასთან განმეორებით კავშირს \\1-ის მეშვეობით, რაც ითხოვს რომ 2 სიმბოლო უნდა გრძელდებოდეს ზუსტად იდენტური 2 სიმბოლოთი. Შესაბამისად ჯგუფმა ნომერმა 0-მა უნდა დააბრუნოს a1a1
Რასაც აკეთებს კიდეც, მაგრამ თუ ოდნავ შევცვლით ტექსტს
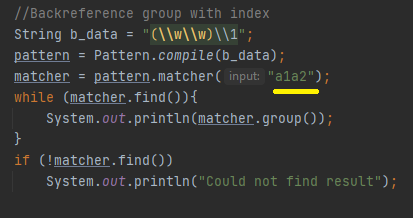
Რეგექსი ტექსტის მოძიებას ვერ შეძლებს, შეგიძლიათ იმდენ ჯგუფთან მოახდინოთ უკუკავშირი რამდენთანაც გსურთ,
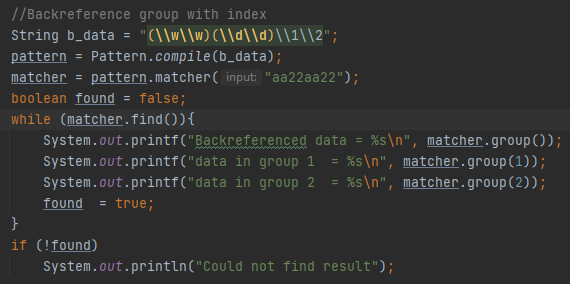
Თუ დაფიქრდებით, უკუკავშირი იდეალური საშუალებაა ტექსტში განმეორებების მოსაძიებლად. Მაღლა ნაჩვენები მაგალითი აბრუნებს შემდეგ რეზულტატს.

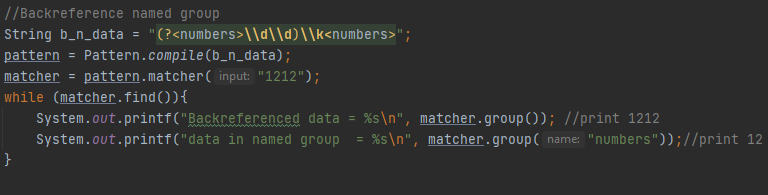
Ჯგუფს შესაძლებელია ექნეს დასახელებაც, რომლის სინტაქსიც არის (?<სახელი>პატერნი)

Რის შემდეგადაც შეგიძლიათ სახელის მეშვეობით გამოიძახოთ ჯგუფი, შესაძლებელია დასახელებულ ჯგუფთან უკუკავშირიც. Რომლის სინტაქსიც არის \\k<სახელი>
Უკუკავშირის გამოყენება შესაძლებელია String-ის ან Matcher-ის replace მეთოდებშიც, თუ უკუკავშირს ვახდენთ ინდექსის მეშვეობით სინტაქსია $n სადაც n არის ჯგუფის ინდექსი, თუ ჯგუფს გააჩნია სახელი მაშინ სინტაქსია ${სახელი}. Მისი გამოყენება საკმაოდ კომფორტულია როცა დიდი ზომის მონაცემებში რამის შეცვლას ვახდენთ, მაგალითზე დიდი ზომის მონაცემებს ვერ გაჩვენებთ მაგრამ ერთ პრიმიტიულ მაგალითს ვნახავთ, რომელმაც წარმოდგენა უნდა შეგიქმნათ, სად და როგორ უნდა გამოიყენოთ იგი.
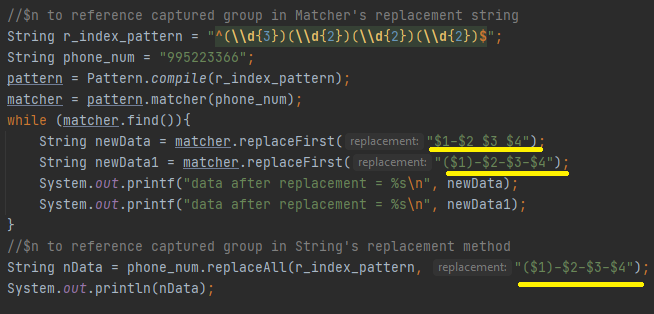
Ფოტოზე ნაჩვენებ მაგალითზე ტელეფონის ნომერი 995223366-ის შეცვლას ვახდენთ, პატერნი ნომერს 4 ნაწილად აჯგუფებს, პირველ ნაწილში ვითხოვთ 3 ციფრს და შემდეგ 3 ნაწილში ვითხოვთ 2 ციფრს, რომ ჯგუფები კარგად გამოვყოთ, ამის შემდეგ შეგვიძლია replace მეთოდში ეს ჯგუფები გამოვიყენოთ ისე როგორც გვჭირდება, პირველ შემთხვევაში სამი ციფრის მერე დეფისი უნდა დაისვას და შემდეგი 6 ციფრი უნდა უნდა დავაჯგუფოთ 2 ციფრებად, რომელთა შორისაც სიცარიელე იქნება, მეორე შემთხვევაში პირველ სამ ციფრს მრგვალ ფრჩხილებში ვაქცევთ და შემდეგი ჯგუფები დეფისით უნდა იყოს გამოყოფილი. Შედეგად კი ვიღებთ

Შეცვლილ ტექსტს, ახლა წარმოიდგინეთ რო გაქვთ ფაილი სადაც რამოდენიმე მილიონი ტელეფონის ნომერია შენახული და გსურთ ეს ტელეფონის ნომრები უფრო წაკითხვადი ტელეფონის ნომრებით ჩაანაცვლოთ. Ასეთ სიტუაციაში სულ რაღაც სტრინგის ერთი ველი იზამს მთლიან მაგიას, ახლა წარმოიდგინეთ რო იგივე უნდა გააკეთოთ რეგექსის ცოდნის გარეშე, მოგიწევთ კლასების და მეთოდების წერა, რომელიც დროს, ენერგიას და რესურსებს მოითხოვს, უფრო უარესი სცენარი თუ გინდათ, წარმოიდგინეთ მსგავსი მოთხოვნა მივიდა ადამიანთან მომხმარებლის მიერ, რომელიც საერთოდ არ არის პროგრამისტი. Სავარაუდოდ რამოდენიმე თვე მოუნდება ხო მოთხოვნის შესრულებას? Კი მოუნდება. Ესეთი ელემენტალური რამეების ცოდნა თქვენ სამუშაო პროცეს საგრძნობლად ამცირებს, თუ მუშაობთ კომპანიაში სადაც დღიული სამუშაო გრაფიკი არის 8 საათი და გაქვთ დავალება რო 15 ტერაბაიტ ფაილში რამე შეცვალოთ, შეგიძლიათ გააკეთოთ 5 წუთში და დანარჩენი 7 საათი და 55 წუთი რამე სხვა აკეთოთ. Ზუსტად იგივე ოპერაციის შესრულება შეგიძლიათ თუ ჯგუფს სახელი გააჩნია.
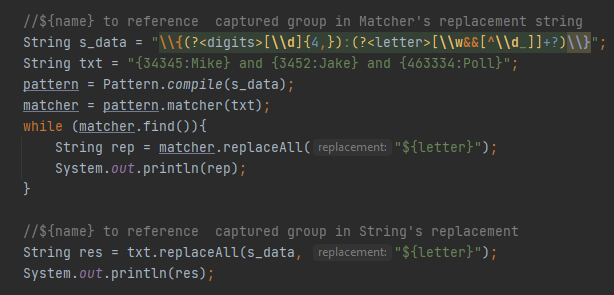
Დაუშვათ გვაქ Json-ის მსგავსი ტექსტი, სადაც მოგვეპოვება id და სახელი მომხრებლის, ჩვენი სურვილი არის რომ მხოლოდ სახელები იყოს ტექსტში, id მისამართები უნდა გავაქროთ, ამისთვის პატერნს ვყობთ 2 ჯგუფად, პირველი ჯგუფი მოიძიებს ციფრებს, რომლის სიდიდეც მინიმუმ 4 ციფრი უნდა იყოს, უნდა გრძელდებოდეს ორი ვერტკალური წერტილით (გამყოფით) და უნდა გრძელდებოდეს ტექსტით, სადაც მხოლოდ ბგერები გვინდა, ციფრების და ქვედა ტირის გამოკლებით, რაოდენობირვი მაჩვენებელად ვიყენებთ ზარმაც მაჩვენებელს რათა მოხდეს ტექსტის სათითაოდ დამუშავება და არა ხარბად, რომელიც ტექსტს მთლიანად დაამუშავებს, ამის შემდეგ ვახდენთ კომპილაციას და მთლიანი ტექსტის შეცვლას ვითხოვთ ${letters} დასახელებული ჯგუფით. Შედეგად კი ვიღებთ.

Საკმაოდ კომფორტულია დამეთანხმებით. Ამით ჯგუფებზე საუბარს მოვრჩით, დაგვრჩა ოპერატორებზე სასაუბრო, რეგექსში გვაქ 2 ოპერატორი, “&-და” ოპერატორი და “|-ან” ოპერატორი. Როგორც წესი “&-და” ოპერატორის გამოყენება ხდება იმპლისიტურად(ავტომატურად), მისი დეფინირების აუცილებლობას არ ვხვდებით, გარდა სიმბოლური კლასისა, რომელსაც ბოლო მაგალითზე ხედავთ. Მაგალითად, როდესაც ჩვენ ვწერთ პატერნს,

Რომელიც ითხოვს მონაცემების ციფრით დაწყებას, რომელსაც შეიძლება მოყვებოდეს დეფისი ან არ მოყვებოდეს და რომელიც უნდა სრულდებოდეს ტექსტით, მაშინ რეგექსი ამას შემდეგნაირად გებულობს , ტექსტი უნდა იწყებოდეს ციფრით “და” უნდა მოყვებოდეს დეფისი “და” უნდა მოყვებოდეს ტექსტი. Ფოტოზე ნაჩვენებ მაგალითზე ტექსტი მოთხოვნას აკმაყოფილებს, შესაბამისად ზუსტად იგივე ტექსტი გამოდის კონზოლში, მაგრამ თუ

Ტექსტი დაიწყება ბგერით, შედეგად ძიება ვერ მოხერხდება.
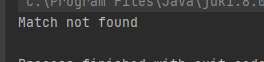
Რადგან დაირღვა “და” ოეპრატორის მოთხოვნა, რომელიც ყველა კლასის მიერ დეფინირებული პატერნის მართებულობას ელის. Იგივე მაგალითზე ტექსტს ბგერით დაწყების საშუალება რო მივცეთ, საკმარისია “|-ან” ოპერატორი გამოვიყენოთ.

Ფოტოზე ნაჩვენებ მაგალითზე ტექსტის დაწყებას ვითხოვთ ციფრით ან დიდი ან პატარა ბგერით, რომელსაც უნდა მოსდევდეს დეფისი ან არ მოსდევდეს და უნდა სრულდებოდეს ტექსტით, კარგად დააკვირდით |-ან ოპერატორის გამოყენებას პატერნში. Უფრო ნათელი რო გახდეს მაგალითი.

Ტექსტი უნდა შეიცავდეს George-ს ან Mike-ს, პირველი ორი ტექსტი პატერნი სასურველ შედეგს, მესამე ვეღარ, რადგან Poll არც ერთ მოთხოვნას არ აკმაყოფილებს. Ამით რეგექსის სინტაქსზე საუბარს მოვრჩით. Დროა განვიხილოთ რას გვთავაზობს რეგექსთან სამუშაოდ java.util.regex პაკეტი, როგორც მაღლა ვთქვი ამ პაკეტში სულ 3 კლასია (+ერთი ინტერფეისი), საუბარს დავიწყებთ Pattern კლასით, სადაც გვაქ ისეთი მეთოდები, როგორიც არის matches, compile, quote და split, ამ 4 მეთოდიდან 2-ის გამოყენების მაგალითი უკვე ნახეთ, მაგრამ სხვაობებს მათ შორის მაინც განვიხილავთ, მაშ ასე, თუ სურვილი გაქვთ რომ უცბად შეამოწმოთ თქვენ მიერ დეფინირებული პატერნით, ტექსტი გადის თუ არა ვალიდაციას შეგიძლიათ matches მეთოდი გამოიყენოთ.

Მაგრამ თუ იცით, რომ თქვენ მიერ დეფინირებული პატერნის გამოყენება მოხდება რამოდენიმეჯერ, მაშინ უკეთესია თუ compile მეთოდს გამოიყენებთ

Რომელიც მოგცემთ საშუალებას ერთი და იგივე პატერნი რამოდენიმე ოპერაციაში, (მეთოდში, კლასში და ა.შ) გამოიყენოთ, რაც მეხსირების დაზოგვაში დაგეხმარებათ, რადგან matches მეთოდი იმდენჯერ ქმნის Pattern ობიეკტს

Რამდენჯერაც გამოიძახებთ, compile მეთოდის ხიბლი მხოლოდ მეხსირების დაზოგვაში არ არის, მას გააჩნია მეორე არგუმენტიც, რომელიც კონსტნტურ ღირებულებებს იღებს Pattern კლასიდან, რომლის დაფაც ასე გამოიყურება.
Მაგალითად სხვა და სხვა ენებში ხშირად შეხვდებით ბგერას რომელიც რამოდენიმე სიმბოლოს შეიცავს, ერთ-ერთი ესეთი ბგერა არის ȯ რომელიც ლათინურ o ბგერას გავს მაგრამ მის თავზე წერტილია მოთავსებული, ბგერის უნიკალური სიმბოლო რომ მივანიჭოთ char პრიმიტიულ ტიპს საკმარისია ამ ბგერის უნიკალური წარმომადგენლობა მოვიძიოთ ინტერნეტში, სადაც ვნახავთ char ტიპისთვის ამ ბგერის მინიჭების ტექსტს, რომელიც ასე გამოიყურება. \u022F
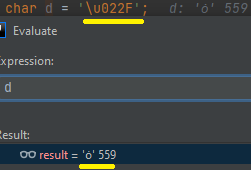
Მაგრამ რა მოხდება იმ შემთხვევაში თუ ხელთ მხოლოდ თავზე მდგომი წერტილის სიმბოლო გვაქ? რომელიც ასე გამოიყურება \u0307, შეგვიძლია წერტილის კომბინირება მოვახდინოთ o ბგერასთან და მოვიძიოთ \u022F სიმბოლო, ამის გაკეთების საშუალებას კანონიკური ტოლობის კონსტანტა მოგვცემს.
Რის შემდეგაც o\u0307

Კანონიკურად უდრის \u022F-ს. Სწორედ ამას ნიშნავს კანონიკური ტოლობა რეგექსში, როცა რამოდენიმე სიმბოლოს ერთობა უდრის სულ სხვა სიმბოლოს. Შემდეგი კონსტანტა დაფაზე არის CASE_INSENSITIVE,
რომელიც ტექსტს, ბგერის ზომის განურჩევლად ადარებს.
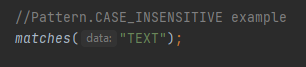
Ამ შემთხვევაში პატერნი text = TEXT-ს, მისი გამოყენება შესაძლებელია პირდაპირ რეგექსის პატერნში, კონსტანტის გამოყენების გარეშე.
Თუ გამოვიყენებთ პრედეფინირებულ (?i) გამოხატულბას. Შემდეგი კონსტანტა არის COMMENTS, რომელიც ახდენს იგნორირებას ცარიელი ადგილების და კომენტარების რეგექსის პატერნში,
მაგალითად პატერნის უკეთ წაკითხვადობისთვის, შეგიძლიათ გამოიყენოთ სიცარიელე (ლურჯი ისრით მითითებული ადგილი ფოტოზე) და კომენტარი. Საკმაოდ მოსახერხებელია მისი გამოყენება თუ პატერნი რომელსაც ქმნით კომპლექსურია, დაკომენტარებით, შემდეგი დეველოპერი ვის ხელშიც მოხვდება თქვენი კოდი მარტივად გაერკვევა რასთან აქვს საქმე. Იგივე ფუნქციონალიზმის გამოყენება შეგიძლიათ პირდაპირ რეგექსის პატერნში

(?x)-ის გამოყენებით. Როგორც იცით . სიმბოლური კლასი წერტილი
ტერმინატორებს(ველის გამყოფებს) არ კითხულობს,

Რაც შედეგად გვაძლევს ერთ მთლიან ტექსტს
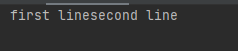
Მაგრამ თუ გამოვიყენებთ DOTALL კონსტანტას
Წერტილი ტერმინატორებსაც წაიკითხავს.

Იგივე კონსტანტის გამოყენება შეგვიძლია პირდაპირ პატერნში (?s) გამოხატულებით.
LITERAL კონსტანტის გამოყენებით, შეგვიძლია რეზერვირებულ ლიტერალებს სპეციალური მნიშვნელობა ჩამოვართვათ, მაგალითად ვიცით რომ () არის ჯგუფის ლიტერალი, რომელიც სიმბოლოების დაჯგუფებას ახდენს,
LITERAL -ან ერთად ჯგუფის ლიტერალები

Უბრალოდ სიმბოლოა
Ყველანაირი ფუნქციონალიზმის გარეშე, იგივე მართალია ყველა სხვა ლიტერალთან მიმართებაშიც. MULTILINE კონსტანტა რას აკეთებს მაღლა ვნახეთ მაგალითებზე, მაგრამ ისევ განვმეორდები, როგორც იცით ^ და $ საზღვრის ლიტერალები, ოპერირებენ ველსი დასაწყისში, მაგრამ მათი ეს ფუნქციონალიზმი სრული დატვირთვით, რომ გამოიყენოთ აუცილებელია MULTILINE კონსტანტის გამოყენებაც, რადგან მის გარეშე ეს ორი საზღვარი ტექსტის დასაწყისში და დასასრულში ოპერირებენ. Ნახეთ მაგალითი.

Სადაც ტექსტის დასაწყისში ნებისმიერი ოდენობის ციფრს ვითხოვთ

Მაგრამ ამ ტექსტის გადაწოდების შემთხვევაში, შედეგად ვიღებთ
123-ს ტექსტის დასაწყისში, თუ MULTILINE-ს ჩავრთავთ

^ საზღვარი თავის სრულ პოტენციალს გამოიყენებს.

Შემდეგი კონსტანტა არის UNICODE_CASE, რომელიც უნიკალური სიმბოლოების ძიების დროს დაგეხმარებათ
Მაგალითად თუ უნიკალურ სიმბოლოს მოიძიებთ რაიმე სახის ტექსტში.
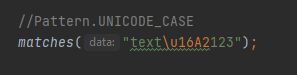
Დაახლოებით იგივეს აკეთებს UNICODE_CHARACTER_CLASS კონსტანტა, რომელიც დამატებით გვაძლევს საშუალებას Posix-ის და პრედეფინირებული კლასების უნიკალურ სიმბოლოებთან ვიმუშაოთ. Მის მაგალითს არ განახებთ, რადგან თუ ნახავთ პრედეფინირებულ კლასებზე და პოსიქსზეც მომიწევს საუბარი, რისი სურვილიც არ მაქ.არსებითად არც კი დაგჭირდებათ მისი გამოყენების ცოდნა რეალურ პროგრამულ ცხოვრებაში. Ბოლო კონსტანტა რომელზეც ვისაუბრებთ არის UNIX_LINES, როგორც წესი ველის გამყოფად აღიქმევა \r ან \n
Თუ ამ პატერნს გამოვიყენებთ,

Ამ ტექსტის წინაშე, შედეგად მივიღებთ

Სადაც ვხედავთ რო ტერმინატორად აღქმულია ორივე სიმბოლო, თუმცა თუ ჩავრთავთ
UNIX_LINES-ს, ტერმინატორად აღიქმევა

Მხოლოდ \n და . სიმბოლური კლასისთვის \r ხელმისაწვდომი ხდება როგორც სიმბოლო, სწორედ ამას ხედავთ კომპილაციის დროს one-ის მერე, სადაც წერტილმა \r მოიძია როგორც სიმბოლო, თუმცა კონზოლში ვერ გამოვიტანეთ. Რადგან ის უბრალოდ კონზოლში არ ჩანს. Ამით პატერნის კონსტანტებზე საუბარს მოვრჩით, მეთოდებიდან ვნახეთ, matches, quote და compile მეთოდის ორივე სახეობა. matches მეთოდის დუბლირება ხდება String კლასშიც, რასაც ეს მეთოდი აკეთებს პატერნ კლასში ზუსტად იგივე აკეთებს String-იც,

Matches-ს მეთოდის გარდა ორივე კლასში split მეთოდიც გვხვდება, Pattern კლასში მეთოდს ვაწოდებთ ტექსტს, რომლის დანაწევრებაც გვინდა, String კლასში მეთოდს ვაწოდებს რეგექს, რომლითაც ტექსტს ვანაწევრებთ, ფოტოზე ნაჩვენებ მაგალითზე ტექსტი გამყოფად შეიცავს ნებისმიერ სიმბოლოს, სწორედ ამ სიმბოლოებზე დაყრდნობით ხდება დანაწევრება და შედეგად გვიბრუნდება მასივი, რომელიც ეკრანზე one, two, three, four და five-ს გამოიტანს.

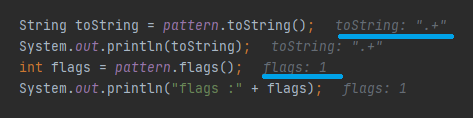
toString მეთოდი გვიბრუნებს პატერნს და flags მეთოდი გვიბრუნებს იმ კონსტანტის ციფრულ ღირებულებას რომელსაც ვიყენებთ, თუ რამოდენიმე კონსტანტას ერთად ვიყენებთ მაშინ მეთოდი ციფრების Bitmask-ს გვიბრუნებს.
\
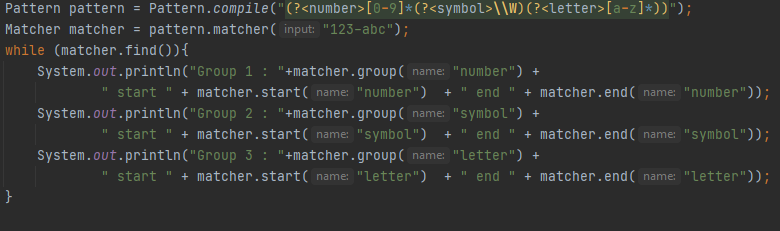
Matcher მეთოდი კი გვიბრუნებს Matcher ობიეკტს, რომელსაც გაცილებით ფართო არჩევანი გააჩნია მეთოდების Pattern კლასთან შედარებით. Ისეთი მეთოდების მაგალითები როგორიც არის group, start და end უკვე ნახეთ, თუმცა ამ მეთოდებსაც აქვთ ნაირსახეობები. Მაგალითად, Group მეთოდს თუ შეუძლია ჯგუფის ინდექსით
ან სახელით გამოძახება, იგივე შეუჩლია start და end მეთოდებსაც, რომლებიც ქვე ჯგუფის საწყის და სასრულ ინდექსებს გვიბრუნებენ.

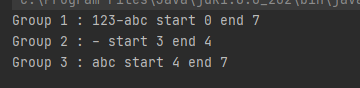
Ინდექსირების მეთოდების მსგავსად ფართო არჩევანი გვაქ ძიების მეთოდებშიც, find მეთოდის მაგალითები ნახეთ მაგრამ ამ მეთოდის გარდა გვაქ კიდევ რამოდნეიმე, როგორიც არის lookingAt და matches, დავიწყოთ find მეთოდით რომელიც პარამეტრად ტექსტის ინდექს იღებს

Რომელიც საშუალებას გაძლევთ სპეციფიური პოზიციიდან დაიწყოთ ძიება, ფოტოზე ნაჩვენებ მაგალითზე ძიებას ვიწყებთ მესამე ინდექსიდან და ყოველ ჯერზე მას ღირებულებას ვუცვლით, რომ გააგრძელოს ტექსტში ძიება აღმავლობით, თუ მას ღირებულებას არ შეუცვლით შემდეგ იტერაციაზე დაბრუნდება და ისევ მესამე ინდექსიდან დაიწყებს ძიებას, პროცეს კი გაიმეორებს გაუთავებლად, ამ გაუთავებელ ლუპში რომ არ აღმოჩდეთ კარგს იზამთ თუ სასურველი ინფორმაციის მოძიების შემთხვევაში ოპერაციიდან გასვლის კონდიციასაც შეარჩევთ, ეს შეიძლება იყოს ძიება აღმავლობით, შეიძლება იყოს break საკვანძო სიტყვა ან ნებისმიერი სხვა რამ რაც თავში აზრად მოგივათ. Შემდეგი მეთოდი არის matches, რომელიც დადებით შედეგს აბრუნებს მხოლოდ იმ შემთხვევაში თუ პატერნი, მთლიან ტექსთან მიმართებაში არის დამაკმაყოფილებელი, დაუშვათ თუ გვაქ

Ტექსტი, რომელიც შეიცავს ციფრებს და ჩვენც ვეძებთ მხოლოდ ციფრებს, მაშინ შედეგად ვიღებთ

Მაგრამ თუ ტექსტ ოდნავ შეცვლით

Მაშინ matches მეთოდის მოთხოვნას, რო მართებული უნდა ვიყოთ მთლიან ტექსთან მიმართებაში ვეღარ დავაკმაყოფილებთ და შედეგად მივიღებთ.
Იგივე სიტუციაში რომ გამოგვეყენებინა lookingAt მეთოდი მაშინ შედეგი დადებითი იქნებოდა, რადგან matches მეთოდისგან განსხვავებით,
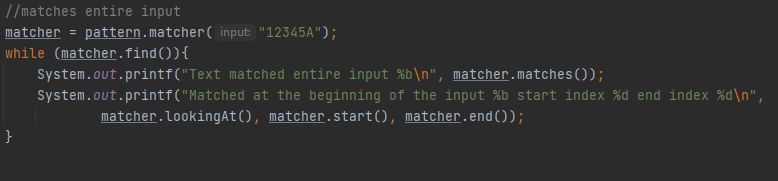
lookingAt მეთოდი ტექსტის მართებულობას პატერნთან მიმართებაში მხოლოდ ტექსტის დასაწყისში ითხოვს.

Თუ გაინტერესებთ ტექსტის დასაწყისი რა სიდიდის არის და რამდენი ინდექსია კონკრეტულად, კონზოლში გამოტანილი რეზულტატი გაცემს ამ კითხვას პასუხს, ტექსტის დასაწყისი ზუსტად იმდენია რამდენიც ეყოფა lookingAt მეთოდს რო მართებული შედეგი დააბრუნოს, ამ კონკრეტულ შემთხვევაში 0-ან ინკლუსიურად მე-5 ინდექსამდე ექსკლუზიურად. Თუ მსგავსი მიდგომა არ გაკმაყოფილებთ და სურვილი გაქვთ ტექსტის კონკრეტულ მონაკვეთზე ამუშაოთ რეგექსი, მაშინ შეგიძლიათ region მეთოდი გამოიყენოთ,
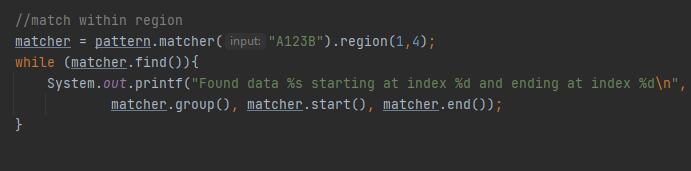
რომელიც პარამეტრად საწყის და სასრულ ინდექსებს იღებს, არ დაგავიწყდეთ, რომ ინდექსირება ინკლუსიურად იწყება და ექსკლუზიურად მთავრდება. Ფოტოზე ნაჩვენები მაგალითი შედეგად 123-ს აბრუნებს, თუ ტექსტს ოდნავ გავზრით.
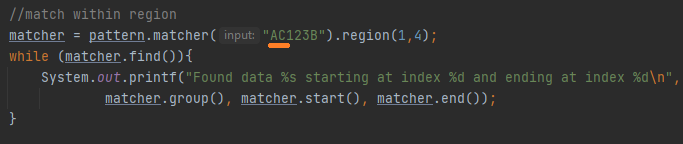
Ძიება დაიწყება C-ან ინკლუსიურად და დამთავრდება 2-ზე ექსკლუზიურად, რაც შედეგად 12-ს მოგვცემს. Replace მეტოდები უკვე ნახეთ ჯგუფებზე საუბრის დროს მაგრამ მაინც ვნახოთ.

replaceFirst და replaceAll მეთოდები, რომლებიც ხელმისაწვდომია Matcher კლასში, ასევე ხელმისაწვდომია String კლასშიც. Ფოტოზე ნაჩვენებ მაგალითზე სიტყვა love-ს ვცვლით ❤ სიმბოლოთი.

Matcher კლაში Replace მეთოდების კიდევ ორი სახეობა appendReplacement და appendTail არის ხელმისაწვდომი
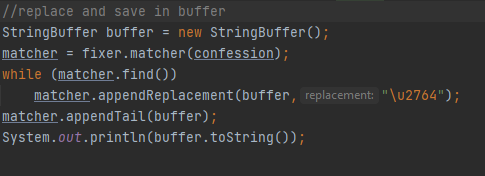
Რომლებიც ბევრად უფრო მოსახერხებელი და მოქნილი არიან ვიდრე replaceFirst და replaceAll მეთოდები, appendReplacement-ს მერე აუცილებლად უნდა გამოიყენოთ appendTail რათა ტექსტის ბოლო დაემატოს ბუფერს, კლასში კიდევ რამოდენიმე უმნიშვნელო მეთოდია, რომლებსაც აღარ გავივლით. Java.util.regex. Პაკეტიდან PatternSyntaxException-ზე დაგვრჩა სასაუბრო, რომელიც არის მარტივი შეუმოწმებელი გამონაკლისი, მისი დახმარებით შეგვიძლია სინტაქსური გამონაკლისები დავიჭიროთ რეგექსიდან, მაგალითად
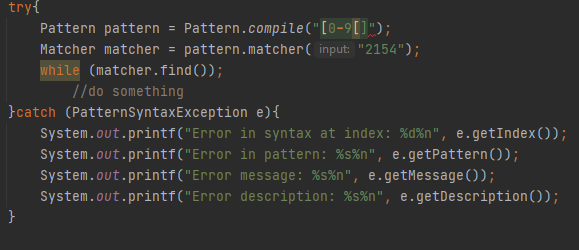
Სინტაქსში გვაქ შეცდომა, ერთით მეტი [-სიმბოლო არის დეფინირებული, compile მეთოდი ისვრის გამონაკლის, რომელიც დეტალურ ინფორმაციას შეიცავს ერორის შესახებ, ინფორმაციის მოძიება შესაძლებელია getIndex, getDescription, getPattern, getMessage მეთოდებით, რომელიც დეფინირებულია PatternSyntaxException კლასში, რაც კომპილაციის შემდეგ აბრუნებს
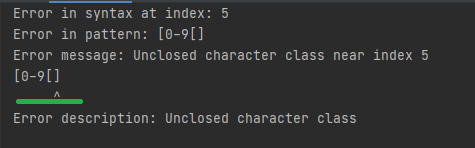
Მსგავს შედეგს, დააკვირდით Error message რამდენად დეტალურ ინფორმაციას შეიცავს, ისრითაც კი არის მითითებული სად არის პრობლემა. Სულ ეს იყო რისი თქმაც შეიძლებოდა რეგექსზე და კლასებზე, რომლითაც მისი გამოყენება შესაძლებელია ჯავაში. Ყველაფერი რაც ამ ბლოგში ვერ მოხვდა ხელმისაწვდომია https://docs.oracle.com/javase/7/docs/api/java/util/regex/Pattern.html ამ ბმულზე. ბლოგში რაც ითქვა იმის 20%-იც კი რო გაითავისოთ საფუძვლიანად, თამამად შეგიძლიათ თქვათ რო რეგექსი იცით, მეტი არც არასდროს დაგჭირდებათ რეალურ პროგრამირებაში, თუ Microsoft excel-ის ან Grammarly-ის დეველოპმენთზე არ მუშაობთ. Მე ამით დაგემშვიდობებით, წარმატებები.
No comments:
Post a Comment