
დაკავშირებული სიები
არის სტუკტურული მონაცემების (Data Structure) ნაწილი და მასზე წესით მასივურ სიებთან,
რიგებთან, სეტებთან, სტაკ და ჰიპთან ერთად უნდა გვესაუბრა, მაგრამ ვინაიდან წინა ბლოგი
იყო ჩაბუდებულ კლასებზე და მომდევნო ბლოგი(ები) იქნება სტრუქტურულ მომაცემებზე, დაკავშირებული
სიები ამ ბლოგში შეითავსებენ ადაპტერის როლს, ჩაბუდებულ კლას გამოვიყენებთ და მომავალ ბლოგზე წარმოდგენა შეგვექმნება. დასახელებაც უხდება სიტუაციას.
კომპიუტერულ მეცნიერებაში
დაკავშირებული სიები არის წრფივი კოლექცია ელემენტების, რომლებიც ერთმანეთან დაკავშირებული
არიან მიმთითებლებით(ცვლადებით)
და ისინი ინახებიან კვანძებში(in
nodes). ყველა კვანძი მეხსიერებაში ინახავს ინფორმაციას რომელიც დაკავშირებულია შემდეგ
კვანძთან, კვანძები ერთად წარმოადგენენ თანმიმდევრობას.
მარტივი ენით რომ ავხსნათ , ყველა კვანძი
ინახავს ინფორმაციას და რეფერენიულ
ცვლადს რომელიც მიგვითითებს შემდეგ ინფორმაციაზე მეხსირებაში. (გახსოვთ იმედია , რომ
რეფერენციული ცვლადი არის მიმთითებელი). ამ სახის ოპერაცია პროგრამისტებს საშუალებას
აძლევს ეფეკტურად დაამატონ და წაშალონ ინფორმაცია მეხსიერებაში, ნებისმიერ ადგილას.
გაიხსენეთ მასივები, მასივი არის განსაზღვრული სიდიდის სტრუკტურული მონაცემი, მას ინფორმაციას
ვერ დავამატებთ და ვერ მოვაკლებთ, როგორც წესი. თუ დეფინრიებული გვაქ მასივი 10 ელემენტით, ის 10 ელემენტი
იქნება მიუხედავად ყველაფრისა(გზები არსებობს თუ როგორ დავამატოთ და მოვაკლოთ მასივს
ელემენტი, მაგრამ ეს არ ითვლება კარგ პრაკტიკად) გამომდინარე აქედან, დაკავშირებული
სიების პრინციპული უპირატესობა მასივთან არის ის, რომ მას ადვილად ვამატებთ და ვაკლებთ
ელემენტს, მაგალითისთვის, თუ მასივში რამის შეცვლა გვინდა მთლიან მასივთან უნდა ვიმუშაოთ,
ყველა ელემენტი უნდა დავამუშაოთ, მოვახდინოთ როტაციები და ა.შ. დაკავშირებულ სიებთან
კი ამის აუცილებლობა არ არსებობს რადგან ის მეხსიერებაში ინახება არა თანმიმდევრულად.
ნახეთ მაგალითი ფოტოზე.


მასივი მეხსიერებაში
ინახება თანმიმდევრულად, მისი ინიციალიზაცია და მეხსიერებაში ალოკაცია ხდება ეგრევე,
თუ გაიხსენებთ სტატიკურ და დინაიურ შეკვრას, მასივი გამოვა სტატიკური კვრა, რადგან
მისი ინიციალიზაცია ხდება კომპილირების დროს, ანუ კომპილატორი ხედავს მეხსიერებაში
სად მოხდა მასივისთვის ადგილის გამოყოფა, განსხვავებით დაკავშირებული სიებისა, სადაც
მეხსიერებაში მისთვის ადგილის გამოყოფა ხდება At Run Time, რაც ნიშნავს იმას რომ ის
იკვრება დინამიურად. ამიტომაც არის მისი ელემენტები მიმოფანტული მეხსიერებაში, მასივის
კი თანმიმდევრულად დალაგებული. თუ გაიხსენებთ მასივს, დაკავშირებული სიების
გათავისება ბევრად გაგიადვილდებათ. თუ არ იცით რა არის მასივი, მიატოვეთ ამ ბლოგის
კითხვა და დაბრუნდით საწყისებთან, სადაც მასივებზე, რეფერენციულ ცვლადებზე, სტექ და
ჰიპ მეხსირებაზე, სტატიკურ და დინაურ შეკვრებზე ვისაუბრეთ. სხვანაირად გაგიჭირდებათ ამ ყველაფრის აღქმა.
მაშ ასე: დაკავშირებული
სიები არის ელემენტების ერთობა, რომელიც ინახება კვანძებში, მათი ერთმანეთან დაკავშირება
კი ხდება რეფერენციული ცვლადის მეშვეობით. დაკავშირებული სია არის აბსტრაკტული ტიპის
დატა, ADT (ADT-ს დეტალურად სტუკტურებზე საუბრის დროს დაუბრუნდები) რაც ნიშნავს იმას რომ მას იყენებს c++, c#, java
და სხვა ენები, ყველა ენას თავის გამოყენების წესი აქვს, ჩვენ ვნახავთ როგორ ხდება
მისი გამოყენება ჯავაში.
უკეთ რო გავერკვეთ
რა არის ელემენტი და რა არის მიმთითებელი, რომელსაც კვანძი ინახავს უნდა დაუბრუნდეთ
მასივს, როგორც მაღლა ავღნიშნე, მასივი მეხსიერებაში ინახება თანმიმდევრულად. როდესაც
კომპილატორი ხედავს რო იქმება მასივი, ის მეხსიერებაში ეძებს ზუსტად იმ სიდიდის ადგილს,
რამდენიც დეფინირებული მასივის ალოკაციისთვის არის საჭირო, ახდენს მის რეზერვირებას
ინიცირებული ელემენტებისთვის, ან იმ ელემენტებისთვის
რომელიც ჯერ არ არის ინცირებული, მაგრამ მომავალში მოხდება მისი ინიციალიზაცია. მაგალითად
int[] a = {1,2,3} ამ შემთხვევაში ზუსტად იცის კომპილატორმა რო 3 ელემენტია მასივში
და ახდენს 12 სლოტის გამოყოფას, int
[] a = new int[100]; a[0] = 1; a[1] =2; a[2] = 3; ინიციალიზაცია
მოხდა 12 სლოტის მაგრამ კომპილატორმა მასივისთვის გამოყო 400 სლოტი და დანარჩენი
388 სლოტი ცარიელია. ამ ყველაფერში საინტერესო
არის ის , თუ როგორ ხდება მეხსიერებაში თანმიმდევრულად განლაგებულ ელემენტებს შორის
კავშირი, ანუ საიდან იცის [1] მასივმა რო მისი შემდეგი ელემენტი [2] მასივშია? დააკვირდით
ფოტოს:


შემდეგ ელემენტზე
მიმთითებელი მასივში არის თვითონ სლოტი, 8 ფოტოზე მოთავსებულია 101,102,103,104 სლოტებე,
მისი მიმთიტებელი კი არის 101, რომელიც მიუთითებს 105 ნომერ სლოტზე სადაც შემდეგი ელემენტია
მასივის შენახული, წარმოიდგინეთ კონტეინერი,


სადაც ყველა შემდეგი
ელემენტი დაკავშირებულია ერთმანეთთან სლოტის ნომერით, ამას მანქანა აკეთებს ჩვენთვის, პირველი ნომერი სლოტის კი გამოდის
რეფერენციული ცვლადი, (პირობითად).
წარმოდგენა შეგვექმნა
როგორ მუშაობს მასივი მეხსირებაში, არ არის რთული, ახლა ვნახოთ როგორ მუშაობს დაკავშიებული
სიები მეხსიერებაში, მასივისგან განსხვავებით დაკავშირებულ სიებში არ გვაქ მსგავსი
ფუფუნება, კომპილატორი არ გვეუბნება სად არის შემდეგი ელემენტი მეხსიერებაში, ის ჩვენ
უნდა მოვნახოთ, მოსანახ ისტრუმენტად კი ვიყენებთ რეფერენციულ ცვლადს. ნახეთ იგივე დიაგრამა,
ამ ჯერად დაკავშირებულ სიებზე.


დააკვირდით როგორ
არის მიმოფანტული ელემენტები მეხსიერებაში, 8,6,7 და 5 არის ელემენტი, რომლებიც იმყოფებიან
გამოყოფილ სლოტებში, ყველა ელემენტის პირველი სლოტის ნომერი არის რეფერენცია შემდეგი
ელემენტის, კონტეინერი რომელიც ინახავს არსებულ რეფერენციას, ელემენტს და შემდეგ რეფერენციას
არის Node.
რეალურ პროგრამირებაში
რა თქმა უნდა სლოტის ნაცვლად რეფერენციულ ცვლადს გამოიყენებთ. ნახეთ მაგალითი:


ფოტოზე ხედავთ
Node-ის შექმნის მაგალითს, რომელიც მიიღებს ელემენტს და რეფერენციულ ცვლადს, ელემენტს
შეინახავს Object და რეფერენციული ცვლადი(მიმთითებელი) შეინახავს დასახელებას რომელიც
მიგვითითებს შემდეგ ელემენტზე მეხსიერებაში. სავარაუდოდ რთულად ჯღერს, ეგრეც არის კომპლექსური
და მრავალ საფეხურიანი ოპერაციების ერთობა გახლავთ სტრუკტურული მონაცემი. მაგრამ წარმოდგენა
უნდა შეგექმნათ რო გამოყენება გაგიადვილდეთ. უფრო გამარტივების მიზნით ვნახოთ ჯავა
ბიბლიოთეკის მიერ შემოთავაზებული დაკავშირებული სიები. დიახ ამის შექმნის აუცილებლობა
არ არსებობს იმიტომ რო უკვე შექმნილია, თქვენ უბრალოდ გამოყენებას ისწავლით. თუმცა
ბლოგის ბოლოში შექვმნით საკუთარ დაკავშირებულ სიას.
ჯავა ბიბლიოთეკის
თანახმად სიას შეუძლია შეინახოს ნებისმიერი სახის ელემენტი, რადგან მუშაობს რეფერენციული
ტიპის დატასთან, Object, String, Integer, Double და ა.შ არ აგერიოთ პრიმიტიული
ტიპის დატაში, int, double, short და ა.შ რეფერენციული
ტიპის დატასთან მუშაობას განაპირობებს null-ის მიღების აუცილებლობა, მეხსიერებას ვერ
გავანულებთ, მას ვა- null-ებთ. თუ მაგალითების ნახვის დროს წავაწყდით პრიმიტიული ტიპის
დატას , მხოლოდ და მხოლოდ ინდექსის მოძებნის მიზნით.
არსებობს სამი სახის
დაკავშირებული სია და ესენია:
Singly Linked List:


რაც ნიშნავს რო ელემენტის
ძიება ხდება ერთი მიმართულებთ. როგორც ფოტოზეა ნაჩვენები.
Doubly Linked List:


სადაც ელემენტების
ძიება ხდება ორმხრივად, ხშირად ბოლო ელემენტს პროგრამისტები head-ს ეძახიან, პირველ
ელემენტს კი tail-ს.
Circular Linked List:


მასში ბოლო ელემენტი
მიუთითებს პირველ ემემენტზე. ან პირიქით.


შესაძლებელია Circular Linked List-ის გამოყენება Single Linked List-ან, ისევე როგორც
Doubly Linked List-ან.
ჩვენ მხოლოდ
Single Linked List-ს განვიხილავთ ამ ბლოგში, დეტალურად მას სტრუკტურებზე საუბრის დროს
დაუბრუნდებით.
მაშ ასე, როგორ
ხდება სიის დეფინირება, მისი გამოყენება და რა მეთოდები გააჩნია ვნახოთ მაგალითებზე:
1. როგორ ხდება ელემენტის
დამატება სიაში:


ახსნა განმარტებას
არ საჭიროებს, საკმაოდ მარტივია.
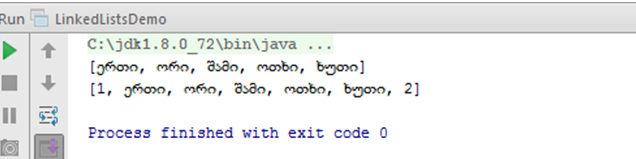
2. შესაძლებელია
ელემენტების სიის თავში ან ბოლოში დამატება:


კომპილირების შემდგომ:

3 შესაძლებელია
ყველა ელემენტის სხვა სიაში გადატანა.


ამის შემდგომ შესაძლებელია
პირველი სიის წაშლა, მეორე სია ინახავს ყველაფერს. კომპილირების შემდგომ:


4 შესაძლებელია პირველი, ბოლო
და ნებისმიერი ელემენტის წაშლა სიიდან:


კომპილირების შემდგომ:


5 შესაძლებელია
ელემენტის ნებისმიერ ინდექსზე ჩანაცვლება, ისევე როგორც შესაძლებელია მთლიანი სიის
ნებისმიერ ინდექსზე ჩანაცვლება.


კომპილირების შემდგომ:


6 შესაძლებელია
სიის შემოწმება, მისი სიდიდის გაგება, და მთლიანად წაშლა.


კომპილირების შემდგომ:


ყველა მეთოდს და
ოპერაციას ვერ განვიხილავთ. რადგან სია ინფორმაცის იღებს 1 კლასის და 4 ინტერფეისისგან. დამატებით მეთოდებს, რომელიც მაგალითებში
ვერ მოხვდნენ მიაგნებთ შემდეგ ბმულზე: https://docs.oracle.com/javase/7/docs/api/java/util/LinkedList.html
დასათაურებას დააკვირდით,
ზოგიერთი მეთოდი არ ეკუთვნის დაკავშირებულ სიებს.
მნიშვნელოვანი უპირატესობები
სიის:
1.
შეუძლია მიიღოს კოპირებული
ელემენტები.
2.
არ ხდება მისი
სინქრონიზება
3. ის არის სწრაფი
რადგან ცვლილების შესატანად არ არის აუცილებელი ელემენტებს ადგილი შეუცვალო,
განსხვავებით მასივისგან.
ჯავა ბიბლიოთეკის
მიერ შემოთაავზებული დაკავშირებული სიები საკმაოდ საინტერესოდ გამოიყურება, ისეთი შეგრძნებაც
რჩება რომ მას ყველაფერი გააჩნია და ჩვენი მხრიდან არაფრის დამატება არ არის საჭირო,
თუმცა არის სიტუაციები როცა გიწევთ საკუთარი სიის შექმნა, რომელიც თქვენ გემოვნებაზე
და მოთხოვნაზე არის მორგებული. შემდეგ ვიდეო ტუტორიალში ნახავთ საკუთარი სიის შექმნის
მაგალითს.
(დააჭირეთ ვიდეო-ს რათა გადახვიდეთ ბმულზე)
პ.ს ამ ბლოგით სრულდება "ჯავა დამწყებთათვის". შემდეგი ბლოგები იქნება მოწინავე ჯავა ტექნოლიგიებზე, Generic, Enum, DataBase, JDBC, JSP, Data Structure's, Regular Expressios, Files & Streams, SQL, HTML, HTML5, CSS, CSS3, Lambda, Data Serialization, JSON & XML, Tomcat, Maven, Servlet's, Design Pattern's, Service's, Tread's, Multi Treads და სხვა მრავალ მნიშვნელოვან ოპერაციებზე.
(დააჭირეთ ვიდეო-ს რათა გადახვიდეთ ბმულზე)
პ.ს ამ ბლოგით სრულდება "ჯავა დამწყებთათვის". შემდეგი ბლოგები იქნება მოწინავე ჯავა ტექნოლიგიებზე, Generic, Enum, DataBase, JDBC, JSP, Data Structure's, Regular Expressios, Files & Streams, SQL, HTML, HTML5, CSS, CSS3, Lambda, Data Serialization, JSON & XML, Tomcat, Maven, Servlet's, Design Pattern's, Service's, Tread's, Multi Treads და სხვა მრავალ მნიშვნელოვან ოპერაციებზე.
No comments:
Post a Comment